mirror of
https://github.com/QwenLM/qwen-code.git
synced 2026-01-18 14:56:20 +00:00
Compare commits
1 Commits
chore/no-t
...
fix/mcp-se
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6f33d92b2c |
@@ -201,11 +201,6 @@ If you encounter issues, check the [troubleshooting guide](https://qwenlm.github
|
||||
|
||||
To report a bug from within the CLI, run `/bug` and include a short title and repro steps.
|
||||
|
||||
## Connect with Us
|
||||
|
||||
- Discord: https://discord.gg/ycKBjdNd
|
||||
- Dingtalk: https://qr.dingtalk.com/action/joingroup?code=v1,k1,+FX6Gf/ZDlTahTIRi8AEQhIaBlqykA0j+eBKKdhLeAE=&_dt_no_comment=1&origin=1
|
||||
|
||||
## Acknowledgments
|
||||
|
||||
This project is based on [Google Gemini CLI](https://github.com/google-gemini/gemini-cli). We acknowledge and appreciate the excellent work of the Gemini CLI team. Our main contribution focuses on parser-level adaptations to better support Qwen-Coder models.
|
||||
|
||||
@@ -202,7 +202,7 @@ This is the most critical stage where files are moved and transformed into their
|
||||
- Copies README.md and LICENSE to dist/
|
||||
- Copies locales folder for internationalization
|
||||
- Creates a clean package.json for distribution with only necessary dependencies
|
||||
- Keeps distribution dependencies minimal (no bundled runtime deps)
|
||||
- Includes runtime dependencies like tiktoken
|
||||
- Maintains optional dependencies for node-pty
|
||||
|
||||
2. The JavaScript Bundle is Created:
|
||||
|
||||
@@ -480,7 +480,7 @@ Arguments passed directly when running the CLI can override other configurations
|
||||
| `--telemetry-otlp-protocol` | | Sets the OTLP protocol for telemetry (`grpc` or `http`). | | Defaults to `grpc`. See [telemetry](../../developers/development/telemetry) for more information. |
|
||||
| `--telemetry-log-prompts` | | Enables logging of prompts for telemetry. | | See [telemetry](../../developers/development/telemetry) for more information. |
|
||||
| `--checkpointing` | | Enables [checkpointing](../features/checkpointing). | | |
|
||||
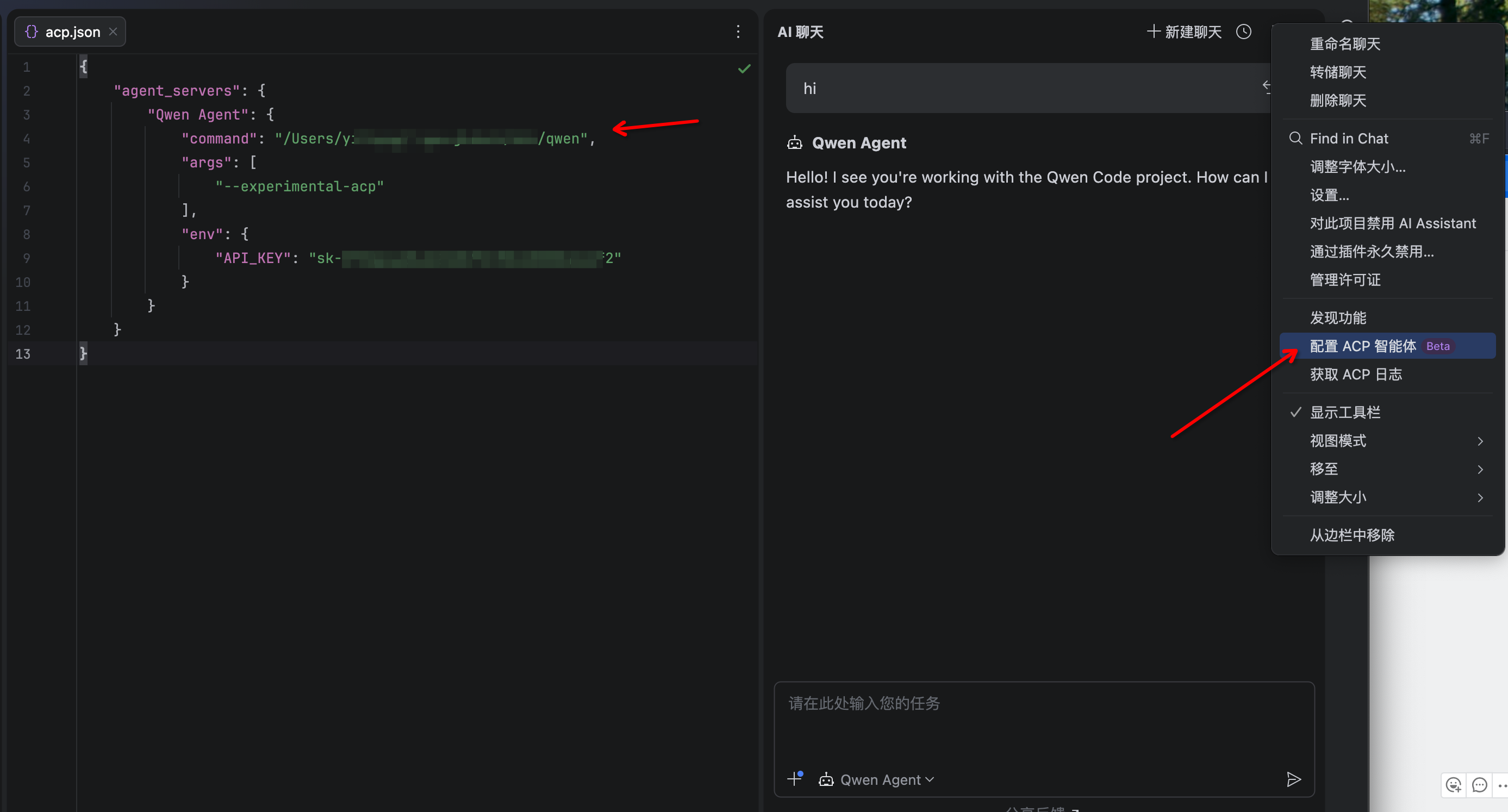
| `--acp` | | Enables ACP mode (Agent Client Protocol). Useful for IDE/editor integrations like [Zed](../integration-zed). | | Stable. Replaces the deprecated `--experimental-acp` flag. |
|
||||
| `--acp` | | Enables ACP mode (Agent Control Protocol). Useful for IDE/editor integrations like [Zed](../integration-zed). | | Stable. Replaces the deprecated `--experimental-acp` flag. |
|
||||
| `--experimental-skills` | | Enables experimental [Agent Skills](../features/skills) (registers the `skill` tool and loads Skills from `.qwen/skills/` and `~/.qwen/skills/`). | | Experimental. |
|
||||
| `--extensions` | `-e` | Specifies a list of extensions to use for the session. | Extension names | If not provided, all available extensions are used. Use the special term `qwen -e none` to disable all extensions. Example: `qwen -e my-extension -e my-other-extension` |
|
||||
| `--list-extensions` | `-l` | Lists all available extensions and exits. | | |
|
||||
|
||||
BIN
docs/users/images/jetbrains-acp.png
Normal file
BIN
docs/users/images/jetbrains-acp.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 36 KiB |
@@ -1,11 +1,11 @@
|
||||
# JetBrains IDEs
|
||||
|
||||
> JetBrains IDEs provide native support for AI coding assistants through the Agent Client Protocol (ACP). This integration allows you to use Qwen Code directly within your JetBrains IDE with real-time code suggestions.
|
||||
> JetBrains IDEs provide native support for AI coding assistants through the Agent Control Protocol (ACP). This integration allows you to use Qwen Code directly within your JetBrains IDE with real-time code suggestions.
|
||||
|
||||
### Features
|
||||
|
||||
- **Native agent experience**: Integrated AI assistant panel within your JetBrains IDE
|
||||
- **Agent Client Protocol**: Full support for ACP enabling advanced IDE interactions
|
||||
- **Agent Control Protocol**: Full support for ACP enabling advanced IDE interactions
|
||||
- **Symbol management**: #-mention files to add them to the conversation context
|
||||
- **Conversation history**: Access to past conversations within the IDE
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
|
||||
4. The Qwen Code agent should now be available in the AI Assistant panel
|
||||
|
||||
|
||||

|
||||
|
||||
## Troubleshooting
|
||||
|
||||
|
||||
@@ -22,7 +22,13 @@
|
||||
|
||||
### Installation
|
||||
|
||||
Download and install the extension from the [Visual Studio Code Extension Marketplace](https://marketplace.visualstudio.com/items?itemName=qwenlm.qwen-code-vscode-ide-companion).
|
||||
1. Install Qwen Code CLI:
|
||||
|
||||
```bash
|
||||
npm install -g qwen-code
|
||||
```
|
||||
|
||||
2. Download and install the extension from the [Visual Studio Code Extension Marketplace](https://marketplace.visualstudio.com/items?itemName=qwenlm.qwen-code-vscode-ide-companion).
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Zed Editor
|
||||
|
||||
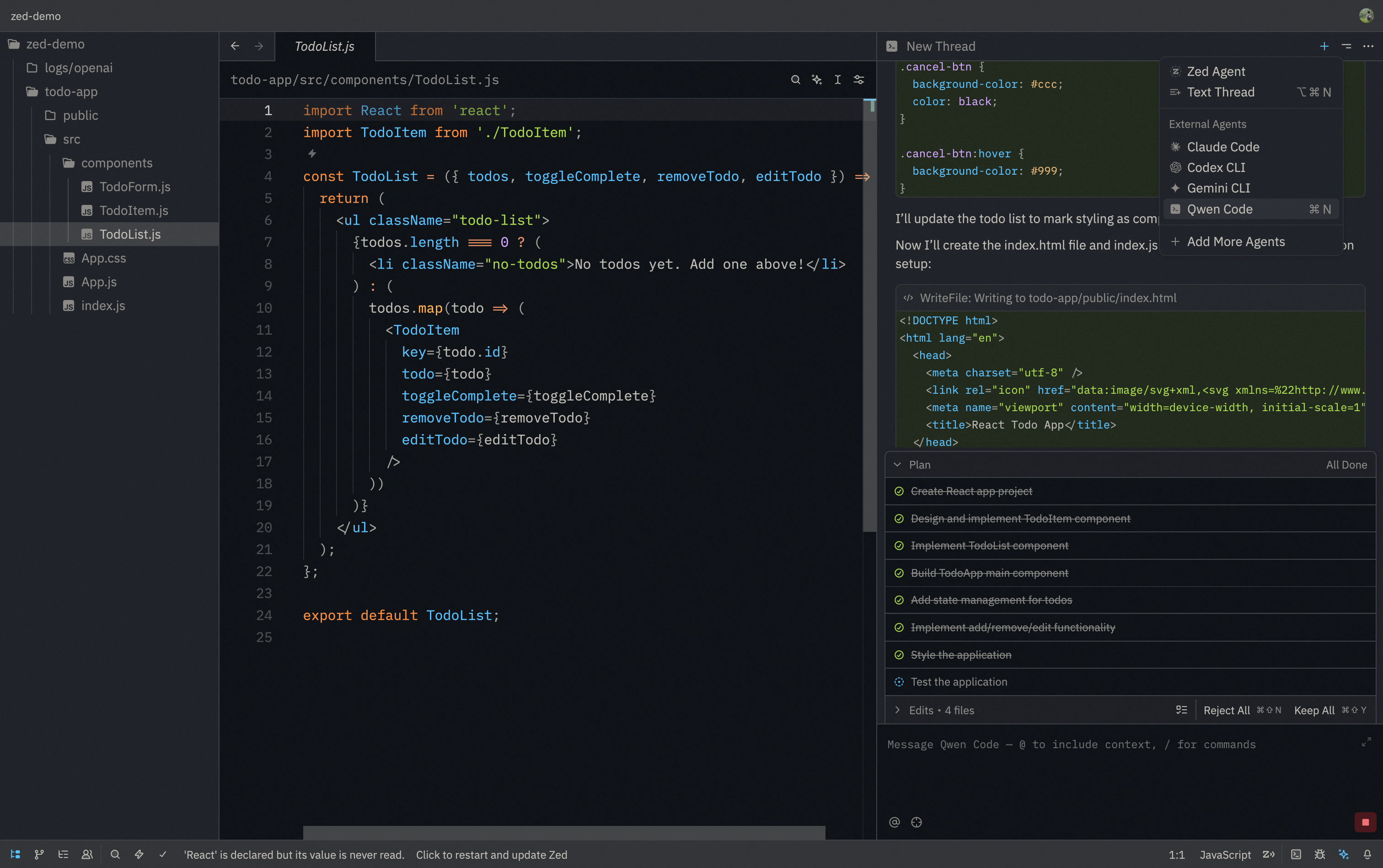
> Zed Editor provides native support for AI coding assistants through the Agent Client Protocol (ACP). This integration allows you to use Qwen Code directly within Zed's interface with real-time code suggestions.
|
||||
> Zed Editor provides native support for AI coding assistants through the Agent Control Protocol (ACP). This integration allows you to use Qwen Code directly within Zed's interface with real-time code suggestions.
|
||||
|
||||
|
||||
|
||||
@@ -20,9 +20,9 @@
|
||||
|
||||
1. Install Qwen Code CLI:
|
||||
|
||||
```bash
|
||||
npm install -g @qwen-code/qwen-code
|
||||
```
|
||||
```bash
|
||||
npm install -g qwen-code
|
||||
```
|
||||
|
||||
2. Download and install [Zed Editor](https://zed.dev/)
|
||||
|
||||
|
||||
@@ -33,6 +33,7 @@ const external = [
|
||||
'@lydell/node-pty-linux-x64',
|
||||
'@lydell/node-pty-win32-arm64',
|
||||
'@lydell/node-pty-win32-x64',
|
||||
'tiktoken',
|
||||
];
|
||||
|
||||
esbuild
|
||||
|
||||
@@ -831,7 +831,7 @@ describe('Permission Control (E2E)', () => {
|
||||
TEST_TIMEOUT,
|
||||
);
|
||||
|
||||
it.skip(
|
||||
it(
|
||||
'should execute dangerous commands without confirmation',
|
||||
async () => {
|
||||
const q = query({
|
||||
|
||||
10
package-lock.json
generated
10
package-lock.json
generated
@@ -15682,6 +15682,12 @@
|
||||
"tslib": "^2"
|
||||
}
|
||||
},
|
||||
"node_modules/tiktoken": {
|
||||
"version": "1.0.22",
|
||||
"resolved": "https://registry.npmjs.org/tiktoken/-/tiktoken-1.0.22.tgz",
|
||||
"integrity": "sha512-PKvy1rVF1RibfF3JlXBSP0Jrcw2uq3yXdgcEXtKTYn3QJ/cBRBHDnrJ5jHky+MENZ6DIPwNUGWpkVx+7joCpNA==",
|
||||
"license": "MIT"
|
||||
},
|
||||
"node_modules/tinybench": {
|
||||
"version": "2.9.0",
|
||||
"resolved": "https://registry.npmjs.org/tinybench/-/tinybench-2.9.0.tgz",
|
||||
@@ -17984,6 +17990,7 @@
|
||||
"shell-quote": "^1.8.3",
|
||||
"simple-git": "^3.28.0",
|
||||
"strip-ansi": "^7.1.0",
|
||||
"tiktoken": "^1.0.21",
|
||||
"undici": "^6.22.0",
|
||||
"uuid": "^9.0.1",
|
||||
"ws": "^8.18.0"
|
||||
@@ -18581,10 +18588,11 @@
|
||||
},
|
||||
"packages/sdk-typescript": {
|
||||
"name": "@qwen-code/sdk",
|
||||
"version": "0.1.3",
|
||||
"version": "0.1.2",
|
||||
"license": "Apache-2.0",
|
||||
"dependencies": {
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"tiktoken": "^1.0.21",
|
||||
"zod": "^3.25.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
|
||||
@@ -38,15 +38,14 @@
|
||||
"dependencies": {
|
||||
"@google/genai": "1.30.0",
|
||||
"@iarna/toml": "^2.2.5",
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"@qwen-code/qwen-code-core": "file:../core",
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"@types/update-notifier": "^6.0.8",
|
||||
"ansi-regex": "^6.2.2",
|
||||
"command-exists": "^1.2.9",
|
||||
"comment-json": "^4.2.5",
|
||||
"diff": "^7.0.0",
|
||||
"dotenv": "^17.1.0",
|
||||
"extract-zip": "^2.0.1",
|
||||
"fzf": "^0.5.2",
|
||||
"glob": "^10.5.0",
|
||||
"highlight.js": "^11.11.1",
|
||||
@@ -66,6 +65,7 @@
|
||||
"strip-json-comments": "^3.1.1",
|
||||
"tar": "^7.5.2",
|
||||
"undici": "^6.22.0",
|
||||
"extract-zip": "^2.0.1",
|
||||
"update-notifier": "^7.3.1",
|
||||
"wrap-ansi": "9.0.2",
|
||||
"yargs": "^17.7.2",
|
||||
@@ -74,7 +74,6 @@
|
||||
"devDependencies": {
|
||||
"@babel/runtime": "^7.27.6",
|
||||
"@google/gemini-cli-test-utils": "file:../test-utils",
|
||||
"@qwen-code/qwen-code-test-utils": "file:../test-utils",
|
||||
"@testing-library/react": "^16.3.0",
|
||||
"@types/archiver": "^6.0.3",
|
||||
"@types/command-exists": "^1.2.3",
|
||||
@@ -93,7 +92,8 @@
|
||||
"pretty-format": "^30.0.2",
|
||||
"react-dom": "^19.1.0",
|
||||
"typescript": "^5.3.3",
|
||||
"vitest": "^3.1.1"
|
||||
"vitest": "^3.1.1",
|
||||
"@qwen-code/qwen-code-test-utils": "file:../test-utils"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=20"
|
||||
|
||||
@@ -83,26 +83,12 @@ export const useAuthCommand = (
|
||||
async (authType: AuthType, credentials?: OpenAICredentials) => {
|
||||
try {
|
||||
const authTypeScope = getPersistScopeForModelSelection(settings);
|
||||
|
||||
// Persist authType
|
||||
settings.setValue(
|
||||
authTypeScope,
|
||||
'security.auth.selectedType',
|
||||
authType,
|
||||
);
|
||||
|
||||
// Persist model from ContentGenerator config (handles fallback cases)
|
||||
// This ensures that when syncAfterAuthRefresh falls back to default model,
|
||||
// it gets persisted to settings.json
|
||||
const contentGeneratorConfig = config.getContentGeneratorConfig();
|
||||
if (contentGeneratorConfig?.model) {
|
||||
settings.setValue(
|
||||
authTypeScope,
|
||||
'model.name',
|
||||
contentGeneratorConfig.model,
|
||||
);
|
||||
}
|
||||
|
||||
// Only update credentials if not switching to QWEN_OAUTH,
|
||||
// so that OpenAI credentials are preserved when switching to QWEN_OAUTH.
|
||||
if (authType !== AuthType.QWEN_OAUTH && credentials) {
|
||||
@@ -120,6 +106,9 @@ export const useAuthCommand = (
|
||||
credentials.baseUrl,
|
||||
);
|
||||
}
|
||||
if (credentials?.model != null) {
|
||||
settings.setValue(authTypeScope, 'model.name', credentials.model);
|
||||
}
|
||||
}
|
||||
} catch (error) {
|
||||
handleAuthFailure(error);
|
||||
|
||||
@@ -8,7 +8,10 @@ import { describe, it, expect, beforeEach, afterEach, vi } from 'vitest';
|
||||
import * as fs from 'node:fs';
|
||||
import * as path from 'node:path';
|
||||
import * as os from 'node:os';
|
||||
import { updateSettingsFilePreservingFormat } from './commentJson.js';
|
||||
import {
|
||||
updateSettingsFilePreservingFormat,
|
||||
applyUpdates,
|
||||
} from './commentJson.js';
|
||||
|
||||
describe('commentJson', () => {
|
||||
let tempDir: string;
|
||||
@@ -180,3 +183,18 @@ describe('commentJson', () => {
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('applyUpdates', () => {
|
||||
it('should apply updates correctly', () => {
|
||||
const original = { a: 1, b: { c: 2 } };
|
||||
const updates = { b: { c: 3 } };
|
||||
const result = applyUpdates(original, updates);
|
||||
expect(result).toEqual({ a: 1, b: { c: 3 } });
|
||||
});
|
||||
it('should apply updates correctly when empty', () => {
|
||||
const original = { a: 1, b: { c: 2 } };
|
||||
const updates = { b: {} };
|
||||
const result = applyUpdates(original, updates);
|
||||
expect(result).toEqual({ a: 1, b: {} });
|
||||
});
|
||||
});
|
||||
|
||||
@@ -38,7 +38,7 @@ export function updateSettingsFilePreservingFormat(
|
||||
fs.writeFileSync(filePath, updatedContent, 'utf-8');
|
||||
}
|
||||
|
||||
function applyUpdates(
|
||||
export function applyUpdates(
|
||||
current: Record<string, unknown>,
|
||||
updates: Record<string, unknown>,
|
||||
): Record<string, unknown> {
|
||||
@@ -50,6 +50,7 @@ function applyUpdates(
|
||||
typeof value === 'object' &&
|
||||
value !== null &&
|
||||
!Array.isArray(value) &&
|
||||
Object.keys(value).length > 0 &&
|
||||
typeof result[key] === 'object' &&
|
||||
result[key] !== null &&
|
||||
!Array.isArray(result[key])
|
||||
|
||||
@@ -120,7 +120,7 @@ export function resolveCliGenerationConfig(
|
||||
|
||||
// Log warnings if any
|
||||
for (const warning of resolved.warnings) {
|
||||
console.warn(warning);
|
||||
console.warn(`[modelProviderUtils] ${warning}`);
|
||||
}
|
||||
|
||||
// Resolve OpenAI logging config (CLI-specific, not part of core resolver)
|
||||
|
||||
@@ -63,6 +63,7 @@
|
||||
"shell-quote": "^1.8.3",
|
||||
"simple-git": "^3.28.0",
|
||||
"strip-ansi": "^7.1.0",
|
||||
"tiktoken": "^1.0.21",
|
||||
"undici": "^6.22.0",
|
||||
"uuid": "^9.0.1",
|
||||
"ws": "^8.18.0"
|
||||
|
||||
@@ -19,7 +19,9 @@ const mockTokenizer = {
|
||||
};
|
||||
|
||||
vi.mock('../../utils/request-tokenizer/index.js', () => ({
|
||||
RequestTokenEstimator: vi.fn(() => mockTokenizer),
|
||||
getDefaultTokenizer: vi.fn(() => mockTokenizer),
|
||||
DefaultRequestTokenizer: vi.fn(() => mockTokenizer),
|
||||
disposeDefaultTokenizer: vi.fn(),
|
||||
}));
|
||||
|
||||
type AnthropicCreateArgs = [unknown, { signal?: AbortSignal }?];
|
||||
@@ -350,7 +352,9 @@ describe('AnthropicContentGenerator', () => {
|
||||
};
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
expect(mockTokenizer.calculateTokens).toHaveBeenCalledWith(request);
|
||||
expect(mockTokenizer.calculateTokens).toHaveBeenCalledWith(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
expect(result.totalTokens).toBe(50);
|
||||
});
|
||||
|
||||
|
||||
@@ -25,7 +25,7 @@ type MessageCreateParamsNonStreaming =
|
||||
Anthropic.MessageCreateParamsNonStreaming;
|
||||
type MessageCreateParamsStreaming = Anthropic.MessageCreateParamsStreaming;
|
||||
type RawMessageStreamEvent = Anthropic.RawMessageStreamEvent;
|
||||
import { RequestTokenEstimator } from '../../utils/request-tokenizer/index.js';
|
||||
import { getDefaultTokenizer } from '../../utils/request-tokenizer/index.js';
|
||||
import { safeJsonParse } from '../../utils/safeJsonParse.js';
|
||||
import { AnthropicContentConverter } from './converter.js';
|
||||
|
||||
@@ -105,8 +105,10 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
request: CountTokensParameters,
|
||||
): Promise<CountTokensResponse> {
|
||||
try {
|
||||
const estimator = new RequestTokenEstimator();
|
||||
const result = await estimator.calculateTokens(request);
|
||||
const tokenizer = getDefaultTokenizer();
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
|
||||
return {
|
||||
totalTokens: result.totalTokens,
|
||||
|
||||
@@ -153,26 +153,6 @@ vi.mock('../telemetry/loggers.js', () => ({
|
||||
logNextSpeakerCheck: vi.fn(),
|
||||
}));
|
||||
|
||||
// Mock RequestTokenizer to use simple character-based estimation
|
||||
vi.mock('../utils/request-tokenizer/requestTokenizer.js', () => ({
|
||||
RequestTokenizer: class {
|
||||
async calculateTokens(request: { contents: unknown }) {
|
||||
// Simple estimation: count characters in JSON and divide by 4
|
||||
const totalChars = JSON.stringify(request.contents).length;
|
||||
return {
|
||||
totalTokens: Math.floor(totalChars / 4),
|
||||
breakdown: {
|
||||
textTokens: Math.floor(totalChars / 4),
|
||||
imageTokens: 0,
|
||||
audioTokens: 0,
|
||||
otherTokens: 0,
|
||||
},
|
||||
processingTime: 0,
|
||||
};
|
||||
}
|
||||
},
|
||||
}));
|
||||
|
||||
/**
|
||||
* Array.fromAsync ponyfill, which will be available in es 2024.
|
||||
*
|
||||
@@ -437,12 +417,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
] as Content[],
|
||||
originalTokenCount = 1000,
|
||||
summaryText = 'This is a summary.',
|
||||
// Token counts returned in usageMetadata to simulate what the API would return
|
||||
// Default values ensure successful compression:
|
||||
// newTokenCount = originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
// = 1000 - (1600 - 1000) + 50 = 1000 - 600 + 50 = 450 (< 1000, success)
|
||||
compressionInputTokenCount = 1600,
|
||||
compressionOutputTokenCount = 50,
|
||||
} = {}) {
|
||||
const mockOriginalChat: Partial<GeminiChat> = {
|
||||
getHistory: vi.fn((_curated?: boolean) => chatHistory),
|
||||
@@ -464,12 +438,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: compressionInputTokenCount,
|
||||
candidatesTokenCount: compressionOutputTokenCount,
|
||||
totalTokenCount:
|
||||
compressionInputTokenCount + compressionOutputTokenCount,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
// Calculate what the new history will be
|
||||
@@ -509,13 +477,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
// New token count formula: originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
const estimatedNewTokenCount = Math.max(
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
originalTokenCount -
|
||||
(compressionInputTokenCount - 1000) +
|
||||
compressionOutputTokenCount,
|
||||
);
|
||||
const estimatedNewTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
return {
|
||||
client,
|
||||
@@ -527,58 +493,49 @@ describe('Gemini Client (client.ts)', () => {
|
||||
|
||||
describe('when compression inflates the token count', () => {
|
||||
it('allows compression to be forced/manual after a failure', async () => {
|
||||
// Call 1 (Fails): Setup with token counts that will inflate
|
||||
// newTokenCount = originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
// = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
// Call 1 (Fails): Setup with a long summary to inflate tokens
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount: inflatedTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(inflatedTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
await client.tryCompressChat('prompt-id-4', false); // Fails
|
||||
|
||||
// Call 2 (Forced): Re-setup with token counts that will compress
|
||||
// newTokenCount = 100 - (1100 - 1000) + 50 = 100 - 100 + 50 = 50 <= 100 (compression)
|
||||
// Call 2 (Forced): Re-setup with a short summary
|
||||
const shortSummary = 'short';
|
||||
const { estimatedNewTokenCount: compressedTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: shortSummary,
|
||||
compressionInputTokenCount: 1100,
|
||||
compressionOutputTokenCount: 50,
|
||||
});
|
||||
expect(compressedTokenCount).toBeLessThanOrEqual(100); // Ensure setup is correct
|
||||
|
||||
const result = await client.tryCompressChat('prompt-id-4', true); // Forced
|
||||
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(100);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(100);
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
newTokenCount: compressedTokenCount,
|
||||
originalTokenCount: 100,
|
||||
});
|
||||
});
|
||||
|
||||
it('yields the result even if the compression inflated the tokens', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
const result = await client.tryCompressChat('prompt-id-4', false);
|
||||
|
||||
expect(result.compressionStatus).toBe(
|
||||
CompressionStatus.COMPRESSION_FAILED_INFLATED_TOKEN_COUNT,
|
||||
);
|
||||
expect(result.originalTokenCount).toBe(100);
|
||||
// The newTokenCount should be higher than original since compression failed due to inflation
|
||||
expect(result.newTokenCount).toBeGreaterThan(100);
|
||||
expect(result).toEqual({
|
||||
compressionStatus:
|
||||
CompressionStatus.COMPRESSION_FAILED_INFLATED_TOKEN_COUNT,
|
||||
newTokenCount: estimatedNewTokenCount,
|
||||
originalTokenCount: 100,
|
||||
});
|
||||
// IMPORTANT: The change in client.ts means setLastPromptTokenCount is NOT called on failure
|
||||
expect(
|
||||
uiTelemetryService.setLastPromptTokenCount,
|
||||
@@ -586,13 +543,10 @@ describe('Gemini Client (client.ts)', () => {
|
||||
});
|
||||
|
||||
it('does not manipulate the source chat', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, mockOriginalChat, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
@@ -603,13 +557,10 @@ describe('Gemini Client (client.ts)', () => {
|
||||
});
|
||||
|
||||
it('will not attempt to compress context after a failure', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
@@ -680,7 +631,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 501 - (1400 - 1000) + 50 = 501 - 400 + 50 = 151 <= 501 (success)
|
||||
const summaryText = 'This is a summary.';
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
@@ -691,11 +641,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1400,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1450,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
// Mock startChat to complete the compression flow
|
||||
@@ -774,8 +719,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 501 - (1400 - 1000) + 50 = 501 - 400 + 50 = 151 <= 501 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -785,11 +735,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1400,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1450,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -799,11 +744,12 @@ describe('Gemini Client (client.ts)', () => {
|
||||
expect(tokenLimit).toHaveBeenCalled();
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
// Assert that summarization happened
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
// Assert that summarization happened and returned the correct stats
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
@@ -863,8 +809,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 700 - (1500 - 1000) + 50 = 700 - 500 + 50 = 250 <= 700 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -874,11 +825,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1500,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1550,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -888,11 +834,12 @@ describe('Gemini Client (client.ts)', () => {
|
||||
expect(tokenLimit).toHaveBeenCalled();
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
// Assert that summarization happened
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
// Assert that summarization happened and returned the correct stats
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
|
||||
@@ -940,8 +887,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 100 - (1060 - 1000) + 20 = 100 - 60 + 20 = 60 <= 100 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -951,11 +903,6 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1060,
|
||||
candidatesTokenCount: 20,
|
||||
totalTokenCount: 1080,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -964,10 +911,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
|
||||
@@ -441,19 +441,47 @@ export class GeminiClient {
|
||||
yield { type: GeminiEventType.ChatCompressed, value: compressed };
|
||||
}
|
||||
|
||||
// Check session token limit after compression.
|
||||
// `lastPromptTokenCount` is treated as authoritative for the (possibly compressed) history;
|
||||
// Check session token limit after compression using accurate token counting
|
||||
const sessionTokenLimit = this.config.getSessionTokenLimit();
|
||||
if (sessionTokenLimit > 0) {
|
||||
const lastPromptTokenCount = uiTelemetryService.getLastPromptTokenCount();
|
||||
if (lastPromptTokenCount > sessionTokenLimit) {
|
||||
// Get all the content that would be sent in an API call
|
||||
const currentHistory = this.getChat().getHistory(true);
|
||||
const userMemory = this.config.getUserMemory();
|
||||
const systemPrompt = getCoreSystemPrompt(
|
||||
userMemory,
|
||||
this.config.getModel(),
|
||||
);
|
||||
const initialHistory = await getInitialChatHistory(this.config);
|
||||
|
||||
// Create a mock request content to count total tokens
|
||||
const mockRequestContent = [
|
||||
{
|
||||
role: 'system' as const,
|
||||
parts: [{ text: systemPrompt }],
|
||||
},
|
||||
...initialHistory,
|
||||
...currentHistory,
|
||||
];
|
||||
|
||||
// Use the improved countTokens method for accurate counting
|
||||
const { totalTokens: totalRequestTokens } = await this.config
|
||||
.getContentGenerator()
|
||||
.countTokens({
|
||||
model: this.config.getModel(),
|
||||
contents: mockRequestContent,
|
||||
});
|
||||
|
||||
if (
|
||||
totalRequestTokens !== undefined &&
|
||||
totalRequestTokens > sessionTokenLimit
|
||||
) {
|
||||
yield {
|
||||
type: GeminiEventType.SessionTokenLimitExceeded,
|
||||
value: {
|
||||
currentTokens: lastPromptTokenCount,
|
||||
currentTokens: totalRequestTokens,
|
||||
limit: sessionTokenLimit,
|
||||
message:
|
||||
`Session token limit exceeded: ${lastPromptTokenCount} tokens > ${sessionTokenLimit} limit. ` +
|
||||
`Session token limit exceeded: ${totalRequestTokens} tokens > ${sessionTokenLimit} limit. ` +
|
||||
'Please start a new session or increase the sessionTokenLimit in your settings.json.',
|
||||
},
|
||||
};
|
||||
|
||||
@@ -708,7 +708,7 @@ describe('GeminiChat', () => {
|
||||
|
||||
// Verify that token counting is called when usageMetadata is present
|
||||
expect(uiTelemetryService.setLastPromptTokenCount).toHaveBeenCalledWith(
|
||||
57,
|
||||
42,
|
||||
);
|
||||
expect(uiTelemetryService.setLastPromptTokenCount).toHaveBeenCalledTimes(
|
||||
1,
|
||||
|
||||
@@ -529,10 +529,10 @@ export class GeminiChat {
|
||||
// Collect token usage for consolidated recording
|
||||
if (chunk.usageMetadata) {
|
||||
usageMetadata = chunk.usageMetadata;
|
||||
const lastPromptTokenCount =
|
||||
usageMetadata.totalTokenCount ?? usageMetadata.promptTokenCount;
|
||||
if (lastPromptTokenCount) {
|
||||
uiTelemetryService.setLastPromptTokenCount(lastPromptTokenCount);
|
||||
if (chunk.usageMetadata.promptTokenCount !== undefined) {
|
||||
uiTelemetryService.setLastPromptTokenCount(
|
||||
chunk.usageMetadata.promptTokenCount,
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -22,7 +22,17 @@ const mockTokenizer = {
|
||||
};
|
||||
|
||||
vi.mock('../../../utils/request-tokenizer/index.js', () => ({
|
||||
RequestTokenEstimator: vi.fn(() => mockTokenizer),
|
||||
getDefaultTokenizer: vi.fn(() => mockTokenizer),
|
||||
DefaultRequestTokenizer: vi.fn(() => mockTokenizer),
|
||||
disposeDefaultTokenizer: vi.fn(),
|
||||
}));
|
||||
|
||||
// Mock tiktoken as well for completeness
|
||||
vi.mock('tiktoken', () => ({
|
||||
get_encoding: vi.fn(() => ({
|
||||
encode: vi.fn(() => new Array(50)), // Mock 50 tokens
|
||||
free: vi.fn(),
|
||||
})),
|
||||
}));
|
||||
|
||||
// Now import the modules that depend on the mocked modules
|
||||
@@ -124,7 +134,7 @@ describe('OpenAIContentGenerator (Refactored)', () => {
|
||||
});
|
||||
|
||||
describe('countTokens', () => {
|
||||
it('should count tokens using character-based estimation', async () => {
|
||||
it('should count tokens using tiktoken', async () => {
|
||||
const request: CountTokensParameters = {
|
||||
contents: [{ role: 'user', parts: [{ text: 'Hello world' }] }],
|
||||
model: 'gpt-4',
|
||||
@@ -132,27 +142,26 @@ describe('OpenAIContentGenerator (Refactored)', () => {
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
|
||||
// 'Hello world' = 11 ASCII chars
|
||||
// 11 / 4 = 2.75 -> ceil = 3 tokens
|
||||
expect(result.totalTokens).toBe(3);
|
||||
expect(result.totalTokens).toBe(50); // Mocked value
|
||||
});
|
||||
|
||||
it('should handle multimodal content', async () => {
|
||||
it('should fall back to character approximation if tiktoken fails', async () => {
|
||||
// Mock tiktoken to throw error
|
||||
vi.doMock('tiktoken', () => ({
|
||||
get_encoding: vi.fn().mockImplementation(() => {
|
||||
throw new Error('Tiktoken failed');
|
||||
}),
|
||||
}));
|
||||
|
||||
const request: CountTokensParameters = {
|
||||
contents: [
|
||||
{
|
||||
role: 'user',
|
||||
parts: [{ text: 'Hello' }, { text: ' world' }],
|
||||
},
|
||||
],
|
||||
contents: [{ role: 'user', parts: [{ text: 'Hello world' }] }],
|
||||
model: 'gpt-4',
|
||||
};
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
|
||||
// Parts are combined for estimation:
|
||||
// 'Hello world' = 11 ASCII chars -> 11/4 = 2.75 -> ceil = 3 tokens
|
||||
expect(result.totalTokens).toBe(3);
|
||||
// Should use character approximation (content length / 4)
|
||||
expect(result.totalTokens).toBeGreaterThan(0);
|
||||
});
|
||||
});
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@ import type {
|
||||
import type { PipelineConfig } from './pipeline.js';
|
||||
import { ContentGenerationPipeline } from './pipeline.js';
|
||||
import { EnhancedErrorHandler } from './errorHandler.js';
|
||||
import { RequestTokenEstimator } from '../../utils/request-tokenizer/index.js';
|
||||
import { getDefaultTokenizer } from '../../utils/request-tokenizer/index.js';
|
||||
import type { ContentGeneratorConfig } from '../contentGenerator.js';
|
||||
|
||||
export class OpenAIContentGenerator implements ContentGenerator {
|
||||
@@ -68,9 +68,11 @@ export class OpenAIContentGenerator implements ContentGenerator {
|
||||
request: CountTokensParameters,
|
||||
): Promise<CountTokensResponse> {
|
||||
try {
|
||||
// Use the request token estimator (character-based).
|
||||
const estimator = new RequestTokenEstimator();
|
||||
const result = await estimator.calculateTokens(request);
|
||||
// Use the new high-performance request tokenizer
|
||||
const tokenizer = getDefaultTokenizer();
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base', // Use GPT-4 encoding for consistency
|
||||
});
|
||||
|
||||
return {
|
||||
totalTokens: result.totalTokens,
|
||||
|
||||
@@ -106,6 +106,15 @@ export const QWEN_OAUTH_MODELS: ModelConfig[] = [
|
||||
description:
|
||||
'The latest Qwen Coder model from Alibaba Cloud ModelStudio (version: qwen3-coder-plus-2025-09-23)',
|
||||
capabilities: { vision: false },
|
||||
generationConfig: {
|
||||
samplingParams: {
|
||||
temperature: 0.7,
|
||||
top_p: 0.9,
|
||||
max_tokens: 8192,
|
||||
},
|
||||
timeout: 60000,
|
||||
maxRetries: 3,
|
||||
},
|
||||
},
|
||||
{
|
||||
id: 'vision-model',
|
||||
@@ -113,5 +122,14 @@ export const QWEN_OAUTH_MODELS: ModelConfig[] = [
|
||||
description:
|
||||
'The latest Qwen Vision model from Alibaba Cloud ModelStudio (version: qwen3-vl-plus-2025-09-23)',
|
||||
capabilities: { vision: true },
|
||||
generationConfig: {
|
||||
samplingParams: {
|
||||
temperature: 0.7,
|
||||
top_p: 0.9,
|
||||
max_tokens: 8192,
|
||||
},
|
||||
timeout: 60000,
|
||||
maxRetries: 3,
|
||||
},
|
||||
},
|
||||
];
|
||||
|
||||
@@ -480,91 +480,6 @@ describe('ModelsConfig', () => {
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should use default model for new authType when switching from different authType with env vars', () => {
|
||||
// Simulate cold start with OPENAI env vars (OPENAI_MODEL and OPENAI_API_KEY)
|
||||
// This sets the model in generationConfig but no authType is selected yet
|
||||
const modelsConfig = new ModelsConfig({
|
||||
generationConfig: {
|
||||
model: 'gpt-4o', // From OPENAI_MODEL env var
|
||||
apiKey: 'openai-key-from-env',
|
||||
},
|
||||
});
|
||||
|
||||
// User switches to qwen-oauth via AuthDialog
|
||||
// refreshAuth calls syncAfterAuthRefresh with the current model (gpt-4o)
|
||||
// which doesn't exist in qwen-oauth registry, so it should use default
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.QWEN_OAUTH, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should use default qwen-oauth model (coder-model), not the OPENAI model
|
||||
expect(gc.model).toBe('coder-model');
|
||||
expect(gc.apiKey).toBe('QWEN_OAUTH_DYNAMIC_TOKEN');
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should clear manual credentials when switching from USE_OPENAI to QWEN_OAUTH', () => {
|
||||
// User manually set credentials for OpenAI
|
||||
const modelsConfig = new ModelsConfig({
|
||||
initialAuthType: AuthType.USE_OPENAI,
|
||||
generationConfig: {
|
||||
model: 'gpt-4o',
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
},
|
||||
});
|
||||
|
||||
// Manually set credentials via updateCredentials
|
||||
modelsConfig.updateCredentials({
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
model: 'gpt-4o',
|
||||
});
|
||||
|
||||
// User switches to qwen-oauth
|
||||
// Since authType is not USE_OPENAI, manual credentials should be cleared
|
||||
// and default qwen-oauth model should be applied
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.QWEN_OAUTH, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should use default qwen-oauth model, not preserve manual OpenAI credentials
|
||||
expect(gc.model).toBe('coder-model');
|
||||
expect(gc.apiKey).toBe('QWEN_OAUTH_DYNAMIC_TOKEN');
|
||||
// baseUrl should be set to qwen-oauth default, not preserved from manual OpenAI config
|
||||
expect(gc.baseUrl).toBe('DYNAMIC_QWEN_OAUTH_BASE_URL');
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should preserve manual credentials when switching to USE_OPENAI', () => {
|
||||
// User manually set credentials
|
||||
const modelsConfig = new ModelsConfig({
|
||||
initialAuthType: AuthType.USE_OPENAI,
|
||||
generationConfig: {
|
||||
model: 'gpt-4o',
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
samplingParams: { temperature: 0.9 },
|
||||
},
|
||||
});
|
||||
|
||||
// Manually set credentials via updateCredentials
|
||||
modelsConfig.updateCredentials({
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
model: 'gpt-4o',
|
||||
});
|
||||
|
||||
// User switches to USE_OPENAI (same or different model)
|
||||
// Since authType is USE_OPENAI, manual credentials should be preserved
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.USE_OPENAI, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should preserve manual credentials
|
||||
expect(gc.model).toBe('gpt-4o');
|
||||
expect(gc.apiKey).toBe('manual-openai-key');
|
||||
expect(gc.baseUrl).toBe('https://manual.example.com/v1');
|
||||
expect(gc.samplingParams?.temperature).toBe(0.9); // Preserved from initial config
|
||||
});
|
||||
|
||||
it('should maintain consistency between currentModelId and _generationConfig.model after initialization', () => {
|
||||
const modelProvidersConfig: ModelProvidersConfig = {
|
||||
openai: [
|
||||
|
||||
@@ -600,7 +600,7 @@ export class ModelsConfig {
|
||||
|
||||
// If credentials were manually set, don't apply modelProvider defaults
|
||||
// Just update the authType and preserve the manually set credentials
|
||||
if (preserveManualCredentials && authType === AuthType.USE_OPENAI) {
|
||||
if (preserveManualCredentials) {
|
||||
this.strictModelProviderSelection = false;
|
||||
this.currentAuthType = authType;
|
||||
if (modelId) {
|
||||
@@ -621,17 +621,7 @@ export class ModelsConfig {
|
||||
this.applyResolvedModelDefaults(resolved);
|
||||
}
|
||||
} else {
|
||||
// If the provided modelId doesn't exist in the registry for the new authType,
|
||||
// use the default model for that authType instead of keeping the old model.
|
||||
// This handles the case where switching from one authType (e.g., OPENAI with
|
||||
// env vars) to another (e.g., qwen-oauth) - we should use the default model
|
||||
// for the new authType, not the old model.
|
||||
this.currentAuthType = authType;
|
||||
const defaultModel =
|
||||
this.modelRegistry.getDefaultModelForAuthType(authType);
|
||||
if (defaultModel) {
|
||||
this.applyResolvedModelDefaults(defaultModel);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -559,109 +559,6 @@ export async function getQwenOAuthClient(
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Displays a formatted box with OAuth device authorization URL.
|
||||
* Uses process.stderr.write() to bypass ConsolePatcher and ensure the auth URL
|
||||
* is always visible to users, especially in non-interactive mode.
|
||||
* Using stderr prevents corruption of structured JSON output (which goes to stdout)
|
||||
* and follows the standard Unix convention of user-facing messages to stderr.
|
||||
*/
|
||||
function showFallbackMessage(verificationUriComplete: string): void {
|
||||
const title = 'Qwen OAuth Device Authorization';
|
||||
const url = verificationUriComplete;
|
||||
const minWidth = 70;
|
||||
const maxWidth = 80;
|
||||
const boxWidth = Math.min(Math.max(title.length + 4, minWidth), maxWidth);
|
||||
|
||||
// Calculate the width needed for the box (account for padding)
|
||||
const contentWidth = boxWidth - 4; // Subtract 2 spaces and 2 border chars
|
||||
|
||||
// Helper to wrap text to fit within box width
|
||||
const wrapText = (text: string, width: number): string[] => {
|
||||
// For URLs, break at any character if too long
|
||||
if (text.startsWith('http://') || text.startsWith('https://')) {
|
||||
const lines: string[] = [];
|
||||
for (let i = 0; i < text.length; i += width) {
|
||||
lines.push(text.substring(i, i + width));
|
||||
}
|
||||
return lines;
|
||||
}
|
||||
|
||||
// For regular text, break at word boundaries
|
||||
const words = text.split(' ');
|
||||
const lines: string[] = [];
|
||||
let currentLine = '';
|
||||
|
||||
for (const word of words) {
|
||||
if (currentLine.length + word.length + 1 <= width) {
|
||||
currentLine += (currentLine ? ' ' : '') + word;
|
||||
} else {
|
||||
if (currentLine) {
|
||||
lines.push(currentLine);
|
||||
}
|
||||
currentLine = word.length > width ? word.substring(0, width) : word;
|
||||
}
|
||||
}
|
||||
if (currentLine) {
|
||||
lines.push(currentLine);
|
||||
}
|
||||
return lines;
|
||||
};
|
||||
|
||||
// Build the box borders with title centered in top border
|
||||
// Format: +--- Title ---+
|
||||
const titleWithSpaces = ' ' + title + ' ';
|
||||
const totalDashes = boxWidth - 2 - titleWithSpaces.length; // Subtract corners and title
|
||||
const leftDashes = Math.floor(totalDashes / 2);
|
||||
const rightDashes = totalDashes - leftDashes;
|
||||
const topBorder =
|
||||
'+' +
|
||||
'-'.repeat(leftDashes) +
|
||||
titleWithSpaces +
|
||||
'-'.repeat(rightDashes) +
|
||||
'+';
|
||||
const emptyLine = '|' + ' '.repeat(boxWidth - 2) + '|';
|
||||
const bottomBorder = '+' + '-'.repeat(boxWidth - 2) + '+';
|
||||
|
||||
// Build content lines
|
||||
const instructionLines = wrapText(
|
||||
'Please visit the following URL in your browser to authorize:',
|
||||
contentWidth,
|
||||
);
|
||||
const urlLines = wrapText(url, contentWidth);
|
||||
const waitingLine = 'Waiting for authorization to complete...';
|
||||
|
||||
// Write the box
|
||||
process.stderr.write('\n' + topBorder + '\n');
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write instructions
|
||||
for (const line of instructionLines) {
|
||||
process.stderr.write(
|
||||
'| ' + line + ' '.repeat(contentWidth - line.length) + ' |\n',
|
||||
);
|
||||
}
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write URL
|
||||
for (const line of urlLines) {
|
||||
process.stderr.write(
|
||||
'| ' + line + ' '.repeat(contentWidth - line.length) + ' |\n',
|
||||
);
|
||||
}
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write waiting message
|
||||
process.stderr.write(
|
||||
'| ' + waitingLine + ' '.repeat(contentWidth - waitingLine.length) + ' |\n',
|
||||
);
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
process.stderr.write(bottomBorder + '\n\n');
|
||||
}
|
||||
|
||||
async function authWithQwenDeviceFlow(
|
||||
client: QwenOAuth2Client,
|
||||
config: Config,
|
||||
@@ -674,50 +571,6 @@ async function authWithQwenDeviceFlow(
|
||||
};
|
||||
qwenOAuth2Events.once(QwenOAuth2Event.AuthCancel, cancelHandler);
|
||||
|
||||
// Helper to check cancellation and return appropriate result
|
||||
const checkCancellation = (): AuthResult | null => {
|
||||
if (!isCancelled) {
|
||||
return null;
|
||||
}
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
};
|
||||
|
||||
// Helper to emit auth progress events
|
||||
const emitAuthProgress = (
|
||||
status: 'polling' | 'success' | 'error' | 'timeout' | 'rate_limit',
|
||||
message: string,
|
||||
): void => {
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, status, message);
|
||||
};
|
||||
|
||||
// Helper to handle browser launch with error handling
|
||||
const launchBrowser = async (url: string): Promise<void> => {
|
||||
try {
|
||||
const childProcess = await open(url);
|
||||
|
||||
// IMPORTANT: Attach an error handler to the returned child process.
|
||||
// Without this, if `open` fails to spawn a process (e.g., `xdg-open` is not found
|
||||
// in a minimal Docker container), it will emit an unhandled 'error' event,
|
||||
// causing the entire Node.js process to crash.
|
||||
if (childProcess) {
|
||||
childProcess.on('error', (err) => {
|
||||
console.debug(
|
||||
'Browser launch failed:',
|
||||
err.message || 'Unknown error',
|
||||
);
|
||||
});
|
||||
}
|
||||
} catch (err) {
|
||||
console.debug(
|
||||
'Failed to open browser:',
|
||||
err instanceof Error ? err.message : 'Unknown error',
|
||||
);
|
||||
}
|
||||
};
|
||||
|
||||
try {
|
||||
// Generate PKCE code verifier and challenge
|
||||
const { code_verifier, code_challenge } = generatePKCEPair();
|
||||
@@ -740,18 +593,56 @@ async function authWithQwenDeviceFlow(
|
||||
// Emit device authorization event for UI integration immediately
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthUri, deviceAuth);
|
||||
|
||||
const showFallbackMessage = () => {
|
||||
console.log('\n=== Qwen OAuth Device Authorization ===');
|
||||
console.log(
|
||||
'Please visit the following URL in your browser to authorize:',
|
||||
);
|
||||
console.log(`\n${deviceAuth.verification_uri_complete}\n`);
|
||||
console.log('Waiting for authorization to complete...\n');
|
||||
};
|
||||
|
||||
// Always show the fallback message in non-interactive environments to ensure
|
||||
// users can see the authorization URL even if browser launching is attempted.
|
||||
// This is critical for headless/remote environments where browser launching
|
||||
// may silently fail without throwing an error.
|
||||
showFallbackMessage(deviceAuth.verification_uri_complete);
|
||||
if (config.isBrowserLaunchSuppressed()) {
|
||||
// Browser launch is suppressed, show fallback message
|
||||
showFallbackMessage();
|
||||
} else {
|
||||
// Try to open the URL in browser, but always show the URL as fallback
|
||||
// to handle cases where browser launch silently fails (e.g., headless servers)
|
||||
showFallbackMessage();
|
||||
try {
|
||||
const childProcess = await open(deviceAuth.verification_uri_complete);
|
||||
|
||||
// Try to open browser if not suppressed
|
||||
if (!config.isBrowserLaunchSuppressed()) {
|
||||
await launchBrowser(deviceAuth.verification_uri_complete);
|
||||
// IMPORTANT: Attach an error handler to the returned child process.
|
||||
// Without this, if `open` fails to spawn a process (e.g., `xdg-open` is not found
|
||||
// in a minimal Docker container), it will emit an unhandled 'error' event,
|
||||
// causing the entire Node.js process to crash.
|
||||
if (childProcess) {
|
||||
childProcess.on('error', (err) => {
|
||||
console.debug(
|
||||
'Browser launch failed:',
|
||||
err.message || 'Unknown error',
|
||||
);
|
||||
});
|
||||
}
|
||||
} catch (err) {
|
||||
console.debug(
|
||||
'Failed to open browser:',
|
||||
err instanceof Error ? err.message : 'Unknown error',
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
emitAuthProgress('polling', 'Waiting for authorization...');
|
||||
// Emit auth progress event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'polling',
|
||||
'Waiting for authorization...',
|
||||
);
|
||||
|
||||
console.debug('Waiting for authorization...\n');
|
||||
|
||||
// Poll for the token
|
||||
@@ -762,9 +653,11 @@ async function authWithQwenDeviceFlow(
|
||||
|
||||
for (let attempt = 0; attempt < maxAttempts; attempt++) {
|
||||
// Check if authentication was cancelled
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
}
|
||||
|
||||
try {
|
||||
@@ -807,7 +700,9 @@ async function authWithQwenDeviceFlow(
|
||||
// minimal stub; cache invalidation is best-effort and should not break auth.
|
||||
}
|
||||
|
||||
emitAuthProgress(
|
||||
// Emit auth progress success event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'success',
|
||||
'Authentication successful! Access token obtained.',
|
||||
);
|
||||
@@ -830,7 +725,9 @@ async function authWithQwenDeviceFlow(
|
||||
pollInterval = 2000; // Reset to default interval
|
||||
}
|
||||
|
||||
emitAuthProgress(
|
||||
// Emit polling progress event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'polling',
|
||||
`Polling... (attempt ${attempt + 1}/${maxAttempts})`,
|
||||
);
|
||||
@@ -860,9 +757,15 @@ async function authWithQwenDeviceFlow(
|
||||
});
|
||||
|
||||
// Check for cancellation after waiting
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'error',
|
||||
message,
|
||||
);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
}
|
||||
|
||||
continue;
|
||||
@@ -890,17 +793,15 @@ async function authWithQwenDeviceFlow(
|
||||
message: string,
|
||||
eventType: 'error' | 'rate_limit' = 'error',
|
||||
): AuthResult => {
|
||||
emitAuthProgress(eventType, message);
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
eventType,
|
||||
message,
|
||||
);
|
||||
console.error('\n' + message);
|
||||
return { success: false, reason, message };
|
||||
};
|
||||
|
||||
// Check for cancellation first
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
}
|
||||
|
||||
// Handle credential caching failures - stop polling immediately
|
||||
if (errorMessage.includes('Failed to cache credentials')) {
|
||||
return handleError('error', errorMessage);
|
||||
@@ -924,14 +825,26 @@ async function authWithQwenDeviceFlow(
|
||||
}
|
||||
|
||||
const message = `Error polling for token: ${errorMessage}`;
|
||||
emitAuthProgress('error', message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
}
|
||||
|
||||
await new Promise((resolve) => setTimeout(resolve, pollInterval));
|
||||
}
|
||||
}
|
||||
|
||||
const timeoutMessage = 'Authorization timeout, please restart the process.';
|
||||
emitAuthProgress('timeout', timeoutMessage);
|
||||
|
||||
// Emit timeout error event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'timeout',
|
||||
timeoutMessage,
|
||||
);
|
||||
|
||||
console.error('\n' + timeoutMessage);
|
||||
return { success: false, reason: 'timeout', message: timeoutMessage };
|
||||
} catch (error: unknown) {
|
||||
@@ -940,7 +853,7 @@ async function authWithQwenDeviceFlow(
|
||||
});
|
||||
const message = `Device authorization flow failed: ${fullErrorMessage}`;
|
||||
|
||||
emitAuthProgress('error', message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
console.error(message);
|
||||
return { success: false, reason: 'error', message };
|
||||
} finally {
|
||||
|
||||
@@ -15,11 +15,13 @@ import { uiTelemetryService } from '../telemetry/uiTelemetry.js';
|
||||
import { tokenLimit } from '../core/tokenLimits.js';
|
||||
import type { GeminiChat } from '../core/geminiChat.js';
|
||||
import type { Config } from '../config/config.js';
|
||||
import { getInitialChatHistory } from '../utils/environmentContext.js';
|
||||
import type { ContentGenerator } from '../core/contentGenerator.js';
|
||||
|
||||
vi.mock('../telemetry/uiTelemetry.js');
|
||||
vi.mock('../core/tokenLimits.js');
|
||||
vi.mock('../telemetry/loggers.js');
|
||||
vi.mock('../utils/environmentContext.js');
|
||||
|
||||
describe('findCompressSplitPoint', () => {
|
||||
it('should throw an error for non-positive numbers', () => {
|
||||
@@ -120,6 +122,9 @@ describe('ChatCompressionService', () => {
|
||||
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(500);
|
||||
vi.mocked(getInitialChatHistory).mockImplementation(
|
||||
async (_config, extraHistory) => extraHistory || [],
|
||||
);
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
@@ -236,7 +241,6 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(mockChat.getHistory).mockReturnValue(history);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(800);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
// newTokenCount = 800 - (1600 - 1000) + 50 = 800 - 600 + 50 = 250 <= 800 (success)
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -245,11 +249,6 @@ describe('ChatCompressionService', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1600,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1650,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -265,7 +264,6 @@ describe('ChatCompressionService', () => {
|
||||
);
|
||||
|
||||
expect(result.info.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.info.newTokenCount).toBe(250); // 800 - (1600 - 1000) + 50
|
||||
expect(result.newHistory).not.toBeNull();
|
||||
expect(result.newHistory![0].parts![0].text).toBe('Summary');
|
||||
expect(mockGenerateContent).toHaveBeenCalled();
|
||||
@@ -282,7 +280,6 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(100);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
// newTokenCount = 100 - (1100 - 1000) + 50 = 100 - 100 + 50 = 50 <= 100 (success)
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -291,11 +288,6 @@ describe('ChatCompressionService', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1100,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1150,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -323,19 +315,15 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(10);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
const longSummary = 'a'.repeat(1000); // Long summary to inflate token count
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
content: {
|
||||
parts: [{ text: 'Summary' }],
|
||||
parts: [{ text: longSummary }],
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1,
|
||||
candidatesTokenCount: 20,
|
||||
totalTokenCount: 21,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -356,48 +344,6 @@ describe('ChatCompressionService', () => {
|
||||
expect(result.newHistory).toBeNull();
|
||||
});
|
||||
|
||||
it('should return FAILED if usage metadata is missing', async () => {
|
||||
const history: Content[] = [
|
||||
{ role: 'user', parts: [{ text: 'msg1' }] },
|
||||
{ role: 'model', parts: [{ text: 'msg2' }] },
|
||||
{ role: 'user', parts: [{ text: 'msg3' }] },
|
||||
{ role: 'model', parts: [{ text: 'msg4' }] },
|
||||
];
|
||||
vi.mocked(mockChat.getHistory).mockReturnValue(history);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(800);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
content: {
|
||||
parts: [{ text: 'Summary' }],
|
||||
},
|
||||
},
|
||||
],
|
||||
// No usageMetadata -> keep original token count
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
} as unknown as ContentGenerator);
|
||||
|
||||
const result = await service.compress(
|
||||
mockChat,
|
||||
mockPromptId,
|
||||
false,
|
||||
mockModel,
|
||||
mockConfig,
|
||||
false,
|
||||
);
|
||||
|
||||
expect(result.info.compressionStatus).toBe(
|
||||
CompressionStatus.COMPRESSION_FAILED_TOKEN_COUNT_ERROR,
|
||||
);
|
||||
expect(result.info.originalTokenCount).toBe(800);
|
||||
expect(result.info.newTokenCount).toBe(800);
|
||||
expect(result.newHistory).toBeNull();
|
||||
});
|
||||
|
||||
it('should return FAILED if summary is empty string', async () => {
|
||||
const history: Content[] = [
|
||||
{ role: 'user', parts: [{ text: 'msg1' }] },
|
||||
|
||||
@@ -14,6 +14,7 @@ import { getCompressionPrompt } from '../core/prompts.js';
|
||||
import { getResponseText } from '../utils/partUtils.js';
|
||||
import { logChatCompression } from '../telemetry/loggers.js';
|
||||
import { makeChatCompressionEvent } from '../telemetry/types.js';
|
||||
import { getInitialChatHistory } from '../utils/environmentContext.js';
|
||||
|
||||
/**
|
||||
* Threshold for compression token count as a fraction of the model's token limit.
|
||||
@@ -162,25 +163,9 @@ export class ChatCompressionService {
|
||||
);
|
||||
const summary = getResponseText(summaryResponse) ?? '';
|
||||
const isSummaryEmpty = !summary || summary.trim().length === 0;
|
||||
const compressionUsageMetadata = summaryResponse.usageMetadata;
|
||||
const compressionInputTokenCount =
|
||||
compressionUsageMetadata?.promptTokenCount;
|
||||
let compressionOutputTokenCount =
|
||||
compressionUsageMetadata?.candidatesTokenCount;
|
||||
if (
|
||||
compressionOutputTokenCount === undefined &&
|
||||
typeof compressionUsageMetadata?.totalTokenCount === 'number' &&
|
||||
typeof compressionInputTokenCount === 'number'
|
||||
) {
|
||||
compressionOutputTokenCount = Math.max(
|
||||
0,
|
||||
compressionUsageMetadata.totalTokenCount - compressionInputTokenCount,
|
||||
);
|
||||
}
|
||||
|
||||
let newTokenCount = originalTokenCount;
|
||||
let extraHistory: Content[] = [];
|
||||
let canCalculateNewTokenCount = false;
|
||||
|
||||
if (!isSummaryEmpty) {
|
||||
extraHistory = [
|
||||
@@ -195,26 +180,16 @@ export class ChatCompressionService {
|
||||
...historyToKeep,
|
||||
];
|
||||
|
||||
// Best-effort token math using *only* model-reported token counts.
|
||||
//
|
||||
// Note: compressionInputTokenCount includes the compression prompt and
|
||||
// the extra "reason in your scratchpad" instruction(approx. 1000 tokens), and
|
||||
// compressionOutputTokenCount may include non-persisted tokens (thoughts).
|
||||
// We accept these inaccuracies to avoid local token estimation.
|
||||
if (
|
||||
typeof compressionInputTokenCount === 'number' &&
|
||||
compressionInputTokenCount > 0 &&
|
||||
typeof compressionOutputTokenCount === 'number' &&
|
||||
compressionOutputTokenCount > 0
|
||||
) {
|
||||
canCalculateNewTokenCount = true;
|
||||
newTokenCount = Math.max(
|
||||
// Use a shared utility to construct the initial history for an accurate token count.
|
||||
const fullNewHistory = await getInitialChatHistory(config, extraHistory);
|
||||
|
||||
// Estimate token count 1 token ≈ 4 characters
|
||||
newTokenCount = Math.floor(
|
||||
fullNewHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
originalTokenCount -
|
||||
(compressionInputTokenCount - 1000) +
|
||||
compressionOutputTokenCount,
|
||||
);
|
||||
}
|
||||
) / 4,
|
||||
);
|
||||
}
|
||||
|
||||
logChatCompression(
|
||||
@@ -222,8 +197,6 @@ export class ChatCompressionService {
|
||||
makeChatCompressionEvent({
|
||||
tokens_before: originalTokenCount,
|
||||
tokens_after: newTokenCount,
|
||||
compression_input_token_count: compressionInputTokenCount,
|
||||
compression_output_token_count: compressionOutputTokenCount,
|
||||
}),
|
||||
);
|
||||
|
||||
@@ -236,16 +209,6 @@ export class ChatCompressionService {
|
||||
compressionStatus: CompressionStatus.COMPRESSION_FAILED_EMPTY_SUMMARY,
|
||||
},
|
||||
};
|
||||
} else if (!canCalculateNewTokenCount) {
|
||||
return {
|
||||
newHistory: null,
|
||||
info: {
|
||||
originalTokenCount,
|
||||
newTokenCount: originalTokenCount,
|
||||
compressionStatus:
|
||||
CompressionStatus.COMPRESSION_FAILED_TOKEN_COUNT_ERROR,
|
||||
},
|
||||
};
|
||||
} else if (newTokenCount > originalTokenCount) {
|
||||
return {
|
||||
newHistory: null,
|
||||
|
||||
@@ -439,27 +439,17 @@ export interface ChatCompressionEvent extends BaseTelemetryEvent {
|
||||
'event.timestamp': string;
|
||||
tokens_before: number;
|
||||
tokens_after: number;
|
||||
compression_input_token_count?: number;
|
||||
compression_output_token_count?: number;
|
||||
}
|
||||
|
||||
export function makeChatCompressionEvent({
|
||||
tokens_before,
|
||||
tokens_after,
|
||||
compression_input_token_count,
|
||||
compression_output_token_count,
|
||||
}: Omit<ChatCompressionEvent, CommonFields>): ChatCompressionEvent {
|
||||
return {
|
||||
'event.name': 'chat_compression',
|
||||
'event.timestamp': new Date().toISOString(),
|
||||
tokens_before,
|
||||
tokens_after,
|
||||
...(compression_input_token_count !== undefined
|
||||
? { compression_input_token_count }
|
||||
: {}),
|
||||
...(compression_output_token_count !== undefined
|
||||
? { compression_output_token_count }
|
||||
: {}),
|
||||
};
|
||||
}
|
||||
|
||||
|
||||
@@ -4,8 +4,37 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
export { RequestTokenizer as RequestTokenEstimator } from './requestTokenizer.js';
|
||||
export { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
import { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
export { TextTokenizer } from './textTokenizer.js';
|
||||
export { ImageTokenizer } from './imageTokenizer.js';
|
||||
|
||||
export type { TokenCalculationResult, ImageMetadata } from './types.js';
|
||||
export type {
|
||||
RequestTokenizer,
|
||||
TokenizerConfig,
|
||||
TokenCalculationResult,
|
||||
ImageMetadata,
|
||||
} from './types.js';
|
||||
|
||||
// Singleton instance for convenient usage
|
||||
let defaultTokenizer: DefaultRequestTokenizer | null = null;
|
||||
|
||||
/**
|
||||
* Get the default request tokenizer instance
|
||||
*/
|
||||
export function getDefaultTokenizer(): DefaultRequestTokenizer {
|
||||
if (!defaultTokenizer) {
|
||||
defaultTokenizer = new DefaultRequestTokenizer();
|
||||
}
|
||||
return defaultTokenizer;
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of the default tokenizer instance
|
||||
*/
|
||||
export async function disposeDefaultTokenizer(): Promise<void> {
|
||||
if (defaultTokenizer) {
|
||||
await defaultTokenizer.dispose();
|
||||
defaultTokenizer = null;
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,15 +4,19 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import { describe, it, expect, beforeEach } from 'vitest';
|
||||
import { RequestTokenizer } from './requestTokenizer.js';
|
||||
import { describe, it, expect, beforeEach, afterEach } from 'vitest';
|
||||
import { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
import type { CountTokensParameters } from '@google/genai';
|
||||
|
||||
describe('RequestTokenEstimator', () => {
|
||||
let tokenizer: RequestTokenizer;
|
||||
describe('DefaultRequestTokenizer', () => {
|
||||
let tokenizer: DefaultRequestTokenizer;
|
||||
|
||||
beforeEach(() => {
|
||||
tokenizer = new RequestTokenizer();
|
||||
tokenizer = new DefaultRequestTokenizer();
|
||||
});
|
||||
|
||||
afterEach(async () => {
|
||||
await tokenizer.dispose();
|
||||
});
|
||||
|
||||
describe('text token calculation', () => {
|
||||
@@ -217,7 +221,25 @@ describe('RequestTokenEstimator', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('images', () => {
|
||||
describe('configuration', () => {
|
||||
it('should use custom text encoding', async () => {
|
||||
const request: CountTokensParameters = {
|
||||
model: 'test-model',
|
||||
contents: [
|
||||
{
|
||||
role: 'user',
|
||||
parts: [{ text: 'Test text for encoding' }],
|
||||
},
|
||||
],
|
||||
};
|
||||
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
|
||||
expect(result.totalTokens).toBeGreaterThan(0);
|
||||
});
|
||||
|
||||
it('should process multiple images serially', async () => {
|
||||
const pngBase64 =
|
||||
'iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mNkYPhfDwAChAI9jU77yQAAAABJRU5ErkJggg==';
|
||||
|
||||
@@ -10,14 +10,18 @@ import type {
|
||||
Part,
|
||||
PartUnion,
|
||||
} from '@google/genai';
|
||||
import type { TokenCalculationResult } from './types.js';
|
||||
import type {
|
||||
RequestTokenizer,
|
||||
TokenizerConfig,
|
||||
TokenCalculationResult,
|
||||
} from './types.js';
|
||||
import { TextTokenizer } from './textTokenizer.js';
|
||||
import { ImageTokenizer } from './imageTokenizer.js';
|
||||
|
||||
/**
|
||||
* Simple request token estimator that handles text and image content serially
|
||||
* Simple request tokenizer that handles text and image content serially
|
||||
*/
|
||||
export class RequestTokenizer {
|
||||
export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
private textTokenizer: TextTokenizer;
|
||||
private imageTokenizer: ImageTokenizer;
|
||||
|
||||
@@ -31,9 +35,15 @@ export class RequestTokenizer {
|
||||
*/
|
||||
async calculateTokens(
|
||||
request: CountTokensParameters,
|
||||
config: TokenizerConfig = {},
|
||||
): Promise<TokenCalculationResult> {
|
||||
const startTime = performance.now();
|
||||
|
||||
// Apply configuration
|
||||
if (config.textEncoding) {
|
||||
this.textTokenizer = new TextTokenizer(config.textEncoding);
|
||||
}
|
||||
|
||||
try {
|
||||
// Process request content and group by type
|
||||
const { textContents, imageContents, audioContents, otherContents } =
|
||||
@@ -102,8 +112,9 @@ export class RequestTokenizer {
|
||||
if (textContents.length === 0) return 0;
|
||||
|
||||
try {
|
||||
// Avoid per-part rounding inflation by estimating once on the combined text.
|
||||
return await this.textTokenizer.calculateTokens(textContents.join(''));
|
||||
const tokenCounts =
|
||||
await this.textTokenizer.calculateTokensBatch(textContents);
|
||||
return tokenCounts.reduce((sum, count) => sum + count, 0);
|
||||
} catch (error) {
|
||||
console.warn('Error calculating text tokens:', error);
|
||||
// Fallback: character-based estimation
|
||||
@@ -166,8 +177,10 @@ export class RequestTokenizer {
|
||||
if (otherContents.length === 0) return 0;
|
||||
|
||||
try {
|
||||
// Treat other content as text, and avoid per-item rounding inflation.
|
||||
return await this.textTokenizer.calculateTokens(otherContents.join(''));
|
||||
// Treat other content as text for token calculation
|
||||
const tokenCounts =
|
||||
await this.textTokenizer.calculateTokensBatch(otherContents);
|
||||
return tokenCounts.reduce((sum, count) => sum + count, 0);
|
||||
} catch (error) {
|
||||
console.warn('Error calculating other content tokens:', error);
|
||||
// Fallback: character-based estimation
|
||||
@@ -251,18 +264,7 @@ export class RequestTokenizer {
|
||||
otherContents,
|
||||
);
|
||||
}
|
||||
return;
|
||||
}
|
||||
|
||||
// Some request shapes (e.g. CountTokensParameters) allow passing parts directly
|
||||
// instead of wrapping them in a { parts: [...] } Content object.
|
||||
this.processPart(
|
||||
content as Part | string,
|
||||
textContents,
|
||||
imageContents,
|
||||
audioContents,
|
||||
otherContents,
|
||||
);
|
||||
}
|
||||
|
||||
/**
|
||||
@@ -324,4 +326,16 @@ export class RequestTokenizer {
|
||||
console.warn('Failed to serialize unknown part type:', error);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of resources
|
||||
*/
|
||||
async dispose(): Promise<void> {
|
||||
try {
|
||||
// Dispose of tokenizers
|
||||
this.textTokenizer.dispose();
|
||||
} catch (error) {
|
||||
console.warn('Error disposing request tokenizer:', error);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,14 +4,36 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import { describe, it, expect, beforeEach } from 'vitest';
|
||||
import { describe, it, expect, vi, beforeEach, afterEach } from 'vitest';
|
||||
import { TextTokenizer } from './textTokenizer.js';
|
||||
|
||||
// Mock tiktoken at the top level with hoisted functions
|
||||
const mockEncode = vi.hoisted(() => vi.fn());
|
||||
const mockFree = vi.hoisted(() => vi.fn());
|
||||
const mockGetEncoding = vi.hoisted(() => vi.fn());
|
||||
|
||||
vi.mock('tiktoken', () => ({
|
||||
get_encoding: mockGetEncoding,
|
||||
}));
|
||||
|
||||
describe('TextTokenizer', () => {
|
||||
let tokenizer: TextTokenizer;
|
||||
let consoleWarnSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
vi.resetAllMocks();
|
||||
consoleWarnSpy = vi.spyOn(console, 'warn').mockImplementation(() => {});
|
||||
|
||||
// Default mock implementation
|
||||
mockGetEncoding.mockReturnValue({
|
||||
encode: mockEncode,
|
||||
free: mockFree,
|
||||
});
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
vi.restoreAllMocks();
|
||||
tokenizer?.dispose();
|
||||
});
|
||||
|
||||
describe('constructor', () => {
|
||||
@@ -20,14 +42,17 @@ describe('TextTokenizer', () => {
|
||||
expect(tokenizer).toBeInstanceOf(TextTokenizer);
|
||||
});
|
||||
|
||||
it('should create tokenizer with custom encoding (for backward compatibility)', () => {
|
||||
tokenizer = new TextTokenizer();
|
||||
it('should create tokenizer with custom encoding', () => {
|
||||
tokenizer = new TextTokenizer('gpt2');
|
||||
expect(tokenizer).toBeInstanceOf(TextTokenizer);
|
||||
// Note: encoding name is accepted but not used
|
||||
});
|
||||
});
|
||||
|
||||
describe('calculateTokens', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should return 0 for empty text', async () => {
|
||||
const result = await tokenizer.calculateTokens('');
|
||||
expect(result).toBe(0);
|
||||
@@ -44,77 +69,99 @@ describe('TextTokenizer', () => {
|
||||
expect(result2).toBe(0);
|
||||
});
|
||||
|
||||
it('should calculate tokens using character-based estimation for ASCII text', async () => {
|
||||
const testText = 'Hello, world!'; // 13 ASCII chars
|
||||
it('should calculate tokens using tiktoken when available', async () => {
|
||||
const testText = 'Hello, world!';
|
||||
const mockTokens = [1, 2, 3, 4, 5]; // 5 tokens
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
// 13 / 4 = 3.25 -> ceil = 4
|
||||
expect(result).toBe(4);
|
||||
});
|
||||
|
||||
it('should calculate tokens for code (ASCII)', async () => {
|
||||
const code = 'function test() { return 42; }'; // 30 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(code);
|
||||
// 30 / 4 = 7.5 -> ceil = 8
|
||||
expect(result).toBe(8);
|
||||
});
|
||||
|
||||
it('should calculate tokens for non-ASCII text (CJK)', async () => {
|
||||
const unicodeText = '你好世界'; // 4 non-ASCII chars
|
||||
const result = await tokenizer.calculateTokens(unicodeText);
|
||||
// 4 * 1.1 = 4.4 -> ceil = 5
|
||||
expect(mockGetEncoding).toHaveBeenCalledWith('cl100k_base');
|
||||
expect(mockEncode).toHaveBeenCalledWith(testText);
|
||||
expect(result).toBe(5);
|
||||
});
|
||||
|
||||
it('should calculate tokens for mixed ASCII and non-ASCII text', async () => {
|
||||
const mixedText = 'Hello 世界'; // 6 ASCII + 2 non-ASCII
|
||||
const result = await tokenizer.calculateTokens(mixedText);
|
||||
// (6 / 4) + (2 * 1.1) = 1.5 + 2.2 = 3.7 -> ceil = 4
|
||||
it('should use fallback calculation when tiktoken fails to load', async () => {
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load tiktoken');
|
||||
});
|
||||
|
||||
const testText = 'Hello, world!'; // 13 characters
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Failed to load tiktoken with encoding cl100k_base:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(13 / 4) = 4
|
||||
expect(result).toBe(4);
|
||||
});
|
||||
|
||||
it('should calculate tokens for emoji', async () => {
|
||||
const emojiText = '🌍'; // 2 UTF-16 code units (non-ASCII)
|
||||
const result = await tokenizer.calculateTokens(emojiText);
|
||||
// 2 * 1.1 = 2.2 -> ceil = 3
|
||||
expect(result).toBe(3);
|
||||
it('should use fallback calculation when encoding fails', async () => {
|
||||
mockEncode.mockImplementation(() => {
|
||||
throw new Error('Encoding failed');
|
||||
});
|
||||
|
||||
const testText = 'Hello, world!'; // 13 characters
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error encoding text with tiktoken:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(13 / 4) = 4
|
||||
expect(result).toBe(4);
|
||||
});
|
||||
|
||||
it('should handle very long text', async () => {
|
||||
const longText = 'a'.repeat(10000); // 10000 ASCII chars
|
||||
const longText = 'a'.repeat(10000);
|
||||
const mockTokens = new Array(2500); // 2500 tokens
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(longText);
|
||||
// 10000 / 4 = 2500 -> ceil = 2500
|
||||
|
||||
expect(result).toBe(2500);
|
||||
});
|
||||
|
||||
it('should handle text with only whitespace', async () => {
|
||||
const whitespaceText = ' \n\t '; // 7 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(whitespaceText);
|
||||
// 7 / 4 = 1.75 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
it('should handle unicode characters', async () => {
|
||||
const unicodeText = '你好世界 🌍';
|
||||
const mockTokens = [1, 2, 3, 4, 5, 6];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(unicodeText);
|
||||
|
||||
expect(result).toBe(6);
|
||||
});
|
||||
|
||||
it('should handle special characters and symbols', async () => {
|
||||
const specialText = '!@#$%^&*()_+-=[]{}|;:,.<>?'; // 26 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(specialText);
|
||||
// 26 / 4 = 6.5 -> ceil = 7
|
||||
expect(result).toBe(7);
|
||||
});
|
||||
it('should use custom encoding when specified', async () => {
|
||||
tokenizer = new TextTokenizer('gpt2');
|
||||
const testText = 'Hello, world!';
|
||||
const mockTokens = [1, 2, 3];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
it('should handle very short text', async () => {
|
||||
const result = await tokenizer.calculateTokens('a');
|
||||
// 1 / 4 = 0.25 -> ceil = 1
|
||||
expect(result).toBe(1);
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(mockGetEncoding).toHaveBeenCalledWith('gpt2');
|
||||
expect(result).toBe(3);
|
||||
});
|
||||
});
|
||||
|
||||
describe('calculateTokensBatch', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should process multiple texts and return token counts', async () => {
|
||||
const texts = ['Hello', 'world', 'test'];
|
||||
mockEncode
|
||||
.mockReturnValueOnce([1, 2]) // 2 tokens for 'Hello'
|
||||
.mockReturnValueOnce([3, 4, 5]) // 3 tokens for 'world'
|
||||
.mockReturnValueOnce([6]); // 1 token for 'test'
|
||||
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
// 'Hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// 'world' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// 'test' = 4 / 4 = 1 -> ceil = 1
|
||||
expect(result).toEqual([2, 2, 1]);
|
||||
|
||||
expect(result).toEqual([2, 3, 1]);
|
||||
expect(mockEncode).toHaveBeenCalledTimes(3);
|
||||
});
|
||||
|
||||
it('should handle empty array', async () => {
|
||||
@@ -124,156 +171,177 @@ describe('TextTokenizer', () => {
|
||||
|
||||
it('should handle array with empty strings', async () => {
|
||||
const texts = ['', 'hello', ''];
|
||||
mockEncode.mockReturnValue([1, 2, 3]); // Only called for 'hello'
|
||||
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
// '' = 0
|
||||
// 'hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// '' = 0
|
||||
expect(result).toEqual([0, 2, 0]);
|
||||
|
||||
expect(result).toEqual([0, 3, 0]);
|
||||
expect(mockEncode).toHaveBeenCalledTimes(1);
|
||||
expect(mockEncode).toHaveBeenCalledWith('hello');
|
||||
});
|
||||
|
||||
it('should handle mixed ASCII and non-ASCII texts', async () => {
|
||||
const texts = ['Hello', '世界', 'Hello 世界'];
|
||||
it('should use fallback calculation when tiktoken fails to load', async () => {
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load tiktoken');
|
||||
});
|
||||
|
||||
const texts = ['Hello', 'world']; // 5 and 5 characters
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
// 'Hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// '世界' = 2 * 1.1 = 2.2 -> ceil = 3
|
||||
// 'Hello 世界' = (6/4) + (2*1.1) = 1.5 + 2.2 = 3.7 -> ceil = 4
|
||||
expect(result).toEqual([2, 3, 4]);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Failed to load tiktoken with encoding cl100k_base:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(5/4) = 2 for both
|
||||
expect(result).toEqual([2, 2]);
|
||||
});
|
||||
|
||||
it('should use fallback calculation when encoding fails during batch processing', async () => {
|
||||
mockEncode.mockImplementation(() => {
|
||||
throw new Error('Encoding failed');
|
||||
});
|
||||
|
||||
const texts = ['Hello', 'world']; // 5 and 5 characters
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error encoding texts with tiktoken:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(5/4) = 2 for both
|
||||
expect(result).toEqual([2, 2]);
|
||||
});
|
||||
|
||||
it('should handle null and undefined values in batch', async () => {
|
||||
const texts = [null, 'hello', undefined, 'world'] as unknown as string[];
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
// null = 0
|
||||
// 'hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// undefined = 0
|
||||
// 'world' = 5 / 4 = 1.25 -> ceil = 2
|
||||
expect(result).toEqual([0, 2, 0, 2]);
|
||||
});
|
||||
mockEncode
|
||||
.mockReturnValueOnce([1, 2, 3]) // 3 tokens for 'hello'
|
||||
.mockReturnValueOnce([4, 5]); // 2 tokens for 'world'
|
||||
|
||||
it('should process large batches efficiently', async () => {
|
||||
const texts = Array.from({ length: 1000 }, (_, i) => `text${i}`);
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
expect(result).toHaveLength(1000);
|
||||
// Verify results are reasonable
|
||||
result.forEach((count) => {
|
||||
expect(count).toBeGreaterThan(0);
|
||||
expect(count).toBeLessThan(10); // 'textNNN' should be less than 10 tokens
|
||||
});
|
||||
|
||||
expect(result).toEqual([0, 3, 0, 2]);
|
||||
});
|
||||
});
|
||||
|
||||
describe('backward compatibility', () => {
|
||||
it('should accept encoding parameter in constructor', () => {
|
||||
const tokenizer1 = new TextTokenizer();
|
||||
const tokenizer2 = new TextTokenizer();
|
||||
const tokenizer3 = new TextTokenizer();
|
||||
|
||||
expect(tokenizer1).toBeInstanceOf(TextTokenizer);
|
||||
expect(tokenizer2).toBeInstanceOf(TextTokenizer);
|
||||
expect(tokenizer3).toBeInstanceOf(TextTokenizer);
|
||||
describe('dispose', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should produce same results regardless of encoding parameter', async () => {
|
||||
const text = 'Hello, world!';
|
||||
const tokenizer1 = new TextTokenizer();
|
||||
const tokenizer2 = new TextTokenizer();
|
||||
const tokenizer3 = new TextTokenizer();
|
||||
it('should free tiktoken encoding when disposing', async () => {
|
||||
// Initialize the encoding by calling calculateTokens
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
const result1 = await tokenizer1.calculateTokens(text);
|
||||
const result2 = await tokenizer2.calculateTokens(text);
|
||||
const result3 = await tokenizer3.calculateTokens(text);
|
||||
tokenizer.dispose();
|
||||
|
||||
// All should use character-based estimation, ignoring encoding parameter
|
||||
expect(result1).toBe(result2);
|
||||
expect(result2).toBe(result3);
|
||||
expect(result1).toBe(4); // 13 / 4 = 3.25 -> ceil = 4
|
||||
expect(mockFree).toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should maintain async interface for calculateTokens', async () => {
|
||||
const result = tokenizer.calculateTokens('test');
|
||||
expect(result).toBeInstanceOf(Promise);
|
||||
await expect(result).resolves.toBe(1);
|
||||
it('should handle disposal when encoding is not initialized', () => {
|
||||
expect(() => tokenizer.dispose()).not.toThrow();
|
||||
expect(mockFree).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should maintain async interface for calculateTokensBatch', async () => {
|
||||
const result = tokenizer.calculateTokensBatch(['test']);
|
||||
expect(result).toBeInstanceOf(Promise);
|
||||
await expect(result).resolves.toEqual([1]);
|
||||
it('should handle disposal when encoding is null', async () => {
|
||||
// Force encoding to be null by making tiktoken fail
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load');
|
||||
});
|
||||
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
expect(() => tokenizer.dispose()).not.toThrow();
|
||||
expect(mockFree).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should handle errors during disposal gracefully', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
mockFree.mockImplementation(() => {
|
||||
throw new Error('Free failed');
|
||||
});
|
||||
|
||||
tokenizer.dispose();
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error freeing tiktoken encoding:',
|
||||
expect.any(Error),
|
||||
);
|
||||
});
|
||||
|
||||
it('should allow multiple calls to dispose', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
tokenizer.dispose();
|
||||
tokenizer.dispose(); // Second call should not throw
|
||||
|
||||
expect(mockFree).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
});
|
||||
|
||||
describe('lazy initialization', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should not initialize tiktoken until first use', () => {
|
||||
expect(mockGetEncoding).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should initialize tiktoken on first calculateTokens call', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
|
||||
it('should not reinitialize tiktoken on subsequent calls', async () => {
|
||||
await tokenizer.calculateTokens('test1');
|
||||
await tokenizer.calculateTokens('test2');
|
||||
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
|
||||
it('should initialize tiktoken on first calculateTokensBatch call', async () => {
|
||||
await tokenizer.calculateTokensBatch(['test']);
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
});
|
||||
|
||||
describe('edge cases', () => {
|
||||
it('should handle text with only newlines', async () => {
|
||||
const text = '\n\n\n'; // 3 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// 3 / 4 = 0.75 -> ceil = 1
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should handle very short text', async () => {
|
||||
const result = await tokenizer.calculateTokens('a');
|
||||
|
||||
if (mockGetEncoding.mock.calls.length > 0) {
|
||||
// If tiktoken was called, use its result
|
||||
expect(mockEncode).toHaveBeenCalledWith('a');
|
||||
} else {
|
||||
// If tiktoken failed, should use fallback: Math.ceil(1/4) = 1
|
||||
expect(result).toBe(1);
|
||||
}
|
||||
});
|
||||
|
||||
it('should handle text with only whitespace', async () => {
|
||||
const whitespaceText = ' \n\t ';
|
||||
const mockTokens = [1];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(whitespaceText);
|
||||
|
||||
expect(result).toBe(1);
|
||||
});
|
||||
|
||||
it('should handle text with tabs', async () => {
|
||||
const text = '\t\t\t\t'; // 4 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// 4 / 4 = 1 -> ceil = 1
|
||||
expect(result).toBe(1);
|
||||
});
|
||||
it('should handle special characters and symbols', async () => {
|
||||
const specialText = '!@#$%^&*()_+-=[]{}|;:,.<>?';
|
||||
const mockTokens = new Array(10);
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
it('should handle surrogate pairs correctly', async () => {
|
||||
// Character outside BMP (Basic Multilingual Plane)
|
||||
const text = '𝕳𝖊𝖑𝖑𝖔'; // Mathematical bold letters (2 UTF-16 units each)
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// Each character is 2 UTF-16 units, all non-ASCII
|
||||
// Total: 10 non-ASCII units
|
||||
// 10 * 1.1 = 11 -> ceil = 11
|
||||
expect(result).toBe(11);
|
||||
});
|
||||
const result = await tokenizer.calculateTokens(specialText);
|
||||
|
||||
it('should handle combining characters', async () => {
|
||||
// e + combining acute accent
|
||||
const text = 'e\u0301'; // 2 chars: 'e' (ASCII) + combining acute (non-ASCII)
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// ASCII: 1 / 4 = 0.25
|
||||
// Non-ASCII: 1 * 1.1 = 1.1
|
||||
// Total: 0.25 + 1.1 = 1.35 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
});
|
||||
|
||||
it('should handle accented characters', async () => {
|
||||
const text = 'café'; // 'caf' = 3 ASCII, 'é' = 1 non-ASCII
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// ASCII: 3 / 4 = 0.75
|
||||
// Non-ASCII: 1 * 1.1 = 1.1
|
||||
// Total: 0.75 + 1.1 = 1.85 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
});
|
||||
|
||||
it('should handle various unicode scripts', async () => {
|
||||
const cyrillic = 'Привет'; // 6 non-ASCII chars
|
||||
const arabic = 'مرحبا'; // 5 non-ASCII chars
|
||||
const japanese = 'こんにちは'; // 5 non-ASCII chars
|
||||
|
||||
const result1 = await tokenizer.calculateTokens(cyrillic);
|
||||
const result2 = await tokenizer.calculateTokens(arabic);
|
||||
const result3 = await tokenizer.calculateTokens(japanese);
|
||||
|
||||
// All should use 1.1 tokens per char
|
||||
expect(result1).toBe(7); // 6 * 1.1 = 6.6 -> ceil = 7
|
||||
expect(result2).toBe(6); // 5 * 1.1 = 5.5 -> ceil = 6
|
||||
expect(result3).toBe(6); // 5 * 1.1 = 5.5 -> ceil = 6
|
||||
});
|
||||
});
|
||||
|
||||
describe('large inputs', () => {
|
||||
it('should handle very long text', async () => {
|
||||
const longText = 'a'.repeat(200000); // 200k characters
|
||||
const result = await tokenizer.calculateTokens(longText);
|
||||
expect(result).toBe(50000); // 200000 / 4
|
||||
});
|
||||
|
||||
it('should handle large batches', async () => {
|
||||
const texts = Array.from({ length: 5000 }, () => 'Hello, world!');
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
expect(result).toHaveLength(5000);
|
||||
expect(result[0]).toBe(4);
|
||||
expect(result).toBe(10);
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
@@ -4,55 +4,94 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import type { TiktokenEncoding, Tiktoken } from 'tiktoken';
|
||||
import { get_encoding } from 'tiktoken';
|
||||
|
||||
/**
|
||||
* Text tokenizer for calculating text tokens using character-based estimation.
|
||||
*
|
||||
* Uses a lightweight character-based approach that is "good enough" for
|
||||
* guardrail features like sessionTokenLimit.
|
||||
*
|
||||
* Algorithm:
|
||||
* - ASCII characters: 0.25 tokens per char (4 chars = 1 token)
|
||||
* - Non-ASCII characters: 1.1 tokens per char (conservative for CJK, emoji, etc.)
|
||||
* Text tokenizer for calculating text tokens using tiktoken
|
||||
*/
|
||||
export class TextTokenizer {
|
||||
private encoding: Tiktoken | null = null;
|
||||
private encodingName: string;
|
||||
|
||||
constructor(encodingName: string = 'cl100k_base') {
|
||||
this.encodingName = encodingName;
|
||||
}
|
||||
|
||||
/**
|
||||
* Initialize the tokenizer (lazy loading)
|
||||
*/
|
||||
private async ensureEncoding(): Promise<void> {
|
||||
if (this.encoding) return;
|
||||
|
||||
try {
|
||||
// Use type assertion since we know the encoding name is valid
|
||||
this.encoding = get_encoding(this.encodingName as TiktokenEncoding);
|
||||
} catch (error) {
|
||||
console.warn(
|
||||
`Failed to load tiktoken with encoding ${this.encodingName}:`,
|
||||
error,
|
||||
);
|
||||
this.encoding = null;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Calculate tokens for text content
|
||||
*
|
||||
* @param text - The text to estimate tokens for
|
||||
* @returns The estimated token count
|
||||
*/
|
||||
async calculateTokens(text: string): Promise<number> {
|
||||
return this.calculateTokensSync(text);
|
||||
}
|
||||
if (!text) return 0;
|
||||
|
||||
/**
|
||||
* Calculate tokens for multiple text strings
|
||||
*
|
||||
* @param texts - Array of text strings to estimate tokens for
|
||||
* @returns Array of token counts corresponding to each input text
|
||||
*/
|
||||
async calculateTokensBatch(texts: string[]): Promise<number[]> {
|
||||
return texts.map((text) => this.calculateTokensSync(text));
|
||||
}
|
||||
await this.ensureEncoding();
|
||||
|
||||
private calculateTokensSync(text: string): number {
|
||||
if (!text || text.length === 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
let asciiChars = 0;
|
||||
let nonAsciiChars = 0;
|
||||
|
||||
for (let i = 0; i < text.length; i++) {
|
||||
const charCode = text.charCodeAt(i);
|
||||
if (charCode < 128) {
|
||||
asciiChars++;
|
||||
} else {
|
||||
nonAsciiChars++;
|
||||
if (this.encoding) {
|
||||
try {
|
||||
return this.encoding.encode(text).length;
|
||||
} catch (error) {
|
||||
console.warn('Error encoding text with tiktoken:', error);
|
||||
}
|
||||
}
|
||||
|
||||
const tokens = asciiChars / 4 + nonAsciiChars * 1.1;
|
||||
return Math.ceil(tokens);
|
||||
// Fallback: rough approximation using character count
|
||||
// This is a conservative estimate: 1 token ≈ 4 characters for most languages
|
||||
return Math.ceil(text.length / 4);
|
||||
}
|
||||
|
||||
/**
|
||||
* Calculate tokens for multiple text strings in parallel
|
||||
*/
|
||||
async calculateTokensBatch(texts: string[]): Promise<number[]> {
|
||||
await this.ensureEncoding();
|
||||
|
||||
if (this.encoding) {
|
||||
try {
|
||||
return texts.map((text) => {
|
||||
if (!text) return 0;
|
||||
// this.encoding may be null, add a null check to satisfy lint
|
||||
return this.encoding ? this.encoding.encode(text).length : 0;
|
||||
});
|
||||
} catch (error) {
|
||||
console.warn('Error encoding texts with tiktoken:', error);
|
||||
// In case of error, return fallback estimation for all texts
|
||||
return texts.map((text) => Math.ceil((text || '').length / 4));
|
||||
}
|
||||
}
|
||||
|
||||
// Fallback for batch processing
|
||||
return texts.map((text) => Math.ceil((text || '').length / 4));
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of resources
|
||||
*/
|
||||
dispose(): void {
|
||||
if (this.encoding) {
|
||||
try {
|
||||
this.encoding.free();
|
||||
} catch (error) {
|
||||
console.warn('Error freeing tiktoken encoding:', error);
|
||||
}
|
||||
this.encoding = null;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,6 +4,8 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import type { CountTokensParameters } from '@google/genai';
|
||||
|
||||
/**
|
||||
* Token calculation result for different content types
|
||||
*/
|
||||
@@ -21,6 +23,14 @@ export interface TokenCalculationResult {
|
||||
processingTime: number;
|
||||
}
|
||||
|
||||
/**
|
||||
* Configuration for token calculation
|
||||
*/
|
||||
export interface TokenizerConfig {
|
||||
/** Custom text tokenizer encoding (defaults to cl100k_base) */
|
||||
textEncoding?: string;
|
||||
}
|
||||
|
||||
/**
|
||||
* Image metadata extracted from base64 data
|
||||
*/
|
||||
@@ -34,3 +44,21 @@ export interface ImageMetadata {
|
||||
/** Size of the base64 data in bytes */
|
||||
dataSize: number;
|
||||
}
|
||||
|
||||
/**
|
||||
* Request tokenizer interface
|
||||
*/
|
||||
export interface RequestTokenizer {
|
||||
/**
|
||||
* Calculate tokens for a request
|
||||
*/
|
||||
calculateTokens(
|
||||
request: CountTokensParameters,
|
||||
config?: TokenizerConfig,
|
||||
): Promise<TokenCalculationResult>;
|
||||
|
||||
/**
|
||||
* Dispose of resources (worker threads, etc.)
|
||||
*/
|
||||
dispose(): Promise<void>;
|
||||
}
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@qwen-code/sdk",
|
||||
"version": "0.1.3",
|
||||
"version": "0.1.2",
|
||||
"description": "TypeScript SDK for programmatic access to qwen-code CLI",
|
||||
"main": "./dist/index.cjs",
|
||||
"module": "./dist/index.mjs",
|
||||
@@ -46,7 +46,8 @@
|
||||
},
|
||||
"dependencies": {
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"zod": "^3.25.0"
|
||||
"zod": "^3.25.0",
|
||||
"tiktoken": "^1.0.21"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/node": "^20.14.0",
|
||||
|
||||
@@ -125,9 +125,8 @@ function normalizeForRegex(dirPath: string): string {
|
||||
function tryResolveCliFromImportMeta(): string | null {
|
||||
try {
|
||||
if (typeof import.meta !== 'undefined' && import.meta.url) {
|
||||
const currentFilePath = fileURLToPath(import.meta.url);
|
||||
const currentDir = path.dirname(currentFilePath);
|
||||
const cliPath = path.join(currentDir, 'cli', 'cli.js');
|
||||
const cliUrl = new URL('./cli/cli.js', import.meta.url);
|
||||
const cliPath = fileURLToPath(cliUrl);
|
||||
if (fs.existsSync(cliPath)) {
|
||||
return cliPath;
|
||||
}
|
||||
|
||||
@@ -98,6 +98,17 @@ console.log('Creating package.json for distribution...');
|
||||
const rootPackageJson = JSON.parse(
|
||||
fs.readFileSync(path.join(rootDir, 'package.json'), 'utf-8'),
|
||||
);
|
||||
const corePackageJson = JSON.parse(
|
||||
fs.readFileSync(
|
||||
path.join(rootDir, 'packages', 'core', 'package.json'),
|
||||
'utf-8',
|
||||
),
|
||||
);
|
||||
|
||||
const runtimeDependencies = {};
|
||||
if (corePackageJson.dependencies?.tiktoken) {
|
||||
runtimeDependencies.tiktoken = corePackageJson.dependencies.tiktoken;
|
||||
}
|
||||
|
||||
// Create a clean package.json for the published package
|
||||
const distPackageJson = {
|
||||
@@ -113,7 +124,7 @@ const distPackageJson = {
|
||||
},
|
||||
files: ['cli.js', 'vendor', '*.sb', 'README.md', 'LICENSE', 'locales'],
|
||||
config: rootPackageJson.config,
|
||||
dependencies: {},
|
||||
dependencies: runtimeDependencies,
|
||||
optionalDependencies: {
|
||||
'@lydell/node-pty': '1.1.0',
|
||||
'@lydell/node-pty-darwin-arm64': '1.1.0',
|
||||
|
||||
Reference in New Issue
Block a user