mirror of
https://github.com/QwenLM/qwen-code.git
synced 2026-01-19 23:36:19 +00:00
Compare commits
33 Commits
fix/1454-s
...
chore/no-t
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c14ddab6fe | ||
|
|
35c865968f | ||
|
|
ff5ea3c6d7 | ||
|
|
0faaac8fa4 | ||
|
|
c2e62b9122 | ||
|
|
f54b62cda3 | ||
|
|
9521987a09 | ||
|
|
d20f2a41a2 | ||
|
|
e3eccb5987 | ||
|
|
22916457cd | ||
|
|
28bc4e6467 | ||
|
|
50bf65b10b | ||
|
|
47c8bc5303 | ||
|
|
e70ecdf3a8 | ||
|
|
117af05122 | ||
|
|
557e6397bb | ||
|
|
f762a62a2e | ||
|
|
ca12772a28 | ||
|
|
cec4b831b6 | ||
|
|
e4dee3a2b2 | ||
|
|
996b9df947 | ||
|
|
64291db926 | ||
|
|
85473210e5 | ||
|
|
c0c94bd4fc | ||
|
|
a8eb858f99 | ||
|
|
adb53a6dc6 | ||
|
|
b33525183f | ||
|
|
2d1934bf2f | ||
|
|
1b7418f91f | ||
|
|
0bd17a2406 | ||
|
|
59be5163fd | ||
|
|
4f664d00ac | ||
|
|
7fdebe8fe6 |
@@ -201,6 +201,11 @@ If you encounter issues, check the [troubleshooting guide](https://qwenlm.github
|
||||
|
||||
To report a bug from within the CLI, run `/bug` and include a short title and repro steps.
|
||||
|
||||
## Connect with Us
|
||||
|
||||
- Discord: https://discord.gg/ycKBjdNd
|
||||
- Dingtalk: https://qr.dingtalk.com/action/joingroup?code=v1,k1,+FX6Gf/ZDlTahTIRi8AEQhIaBlqykA0j+eBKKdhLeAE=&_dt_no_comment=1&origin=1
|
||||
|
||||
## Acknowledgments
|
||||
|
||||
This project is based on [Google Gemini CLI](https://github.com/google-gemini/gemini-cli). We acknowledge and appreciate the excellent work of the Gemini CLI team. Our main contribution focuses on parser-level adaptations to better support Qwen-Coder models.
|
||||
|
||||
@@ -202,7 +202,7 @@ This is the most critical stage where files are moved and transformed into their
|
||||
- Copies README.md and LICENSE to dist/
|
||||
- Copies locales folder for internationalization
|
||||
- Creates a clean package.json for distribution with only necessary dependencies
|
||||
- Includes runtime dependencies like tiktoken
|
||||
- Keeps distribution dependencies minimal (no bundled runtime deps)
|
||||
- Maintains optional dependencies for node-pty
|
||||
|
||||
2. The JavaScript Bundle is Created:
|
||||
|
||||
@@ -10,4 +10,5 @@ export default {
|
||||
'web-search': 'Web Search',
|
||||
memory: 'Memory',
|
||||
'mcp-server': 'MCP Servers',
|
||||
sandbox: 'Sandboxing',
|
||||
};
|
||||
|
||||
90
docs/developers/tools/sandbox.md
Normal file
90
docs/developers/tools/sandbox.md
Normal file
@@ -0,0 +1,90 @@
|
||||
## Customizing the sandbox environment (Docker/Podman)
|
||||
|
||||
### Currently, the project does not support the use of the BUILD_SANDBOX function after installation through the npm package
|
||||
|
||||
1. To build a custom sandbox, you need to access the build scripts (scripts/build_sandbox.js) in the source code repository.
|
||||
2. These build scripts are not included in the packages released by npm.
|
||||
3. The code contains hard-coded path checks that explicitly reject build requests from non-source code environments.
|
||||
|
||||
If you need extra tools inside the container (e.g., `git`, `python`, `rg`), create a custom Dockerfile, The specific operation is as follows
|
||||
|
||||
#### 1、Clone qwen code project first, https://github.com/QwenLM/qwen-code.git
|
||||
|
||||
#### 2、Make sure you perform the following operation in the source code repository directory
|
||||
|
||||
```bash
|
||||
# 1. First, install the dependencies of the project
|
||||
npm install
|
||||
|
||||
# 2. Build the Qwen Code project
|
||||
npm run build
|
||||
|
||||
# 3. Verify that the dist directory has been generated
|
||||
ls -la packages/cli/dist/
|
||||
|
||||
# 4. Create a global link in the CLI package directory
|
||||
cd packages/cli
|
||||
npm link
|
||||
|
||||
# 5. Verification link (it should now point to the source code)
|
||||
which qwen
|
||||
# Expected output: /xxx/xxx/.nvm/versions/node/v24.11.1/bin/qwen
|
||||
# Or similar paths, but it should be a symbolic link
|
||||
|
||||
# 6. For details of the symbolic link, you can see the specific source code path
|
||||
ls -la $(dirname $(which qwen))/../lib/node_modules/@qwen-code/qwen-code
|
||||
# It should show that this is a symbolic link pointing to your source code directory
|
||||
|
||||
# 7.Test the version of qwen
|
||||
qwen -v
|
||||
# npm link will overwrite the global qwen. To avoid being unable to distinguish the same version number, you can uninstall the global CLI first
|
||||
```
|
||||
|
||||
#### 3、Create your sandbox Dockerfile under the root directory of your own project
|
||||
|
||||
- Path: `.qwen/sandbox.Dockerfile`
|
||||
|
||||
- Official mirror image address:https://github.com/QwenLM/qwen-code/pkgs/container/qwen-code
|
||||
|
||||
```bash
|
||||
# Based on the official Qwen sandbox image (It is recommended to explicitly specify the version)
|
||||
FROM ghcr.io/qwenlm/qwen-code:sha-570ec43
|
||||
# Add your extra tools here
|
||||
RUN apt-get update && apt-get install -y \
|
||||
git \
|
||||
python3 \
|
||||
ripgrep
|
||||
```
|
||||
|
||||
#### 4、Create the first sandbox image under the root directory of your project
|
||||
|
||||
```bash
|
||||
GEMINI_SANDBOX=docker BUILD_SANDBOX=1 qwen -s
|
||||
# Observe whether the sandbox version of the tool you launched is consistent with the version of your custom image. If they are consistent, the startup will be successful
|
||||
```
|
||||
|
||||
This builds a project-specific image based on the default sandbox image.
|
||||
|
||||
#### Remove npm link
|
||||
|
||||
- If you want to restore the official CLI of qwen, please remove the npm link
|
||||
|
||||
```bash
|
||||
# Method 1: Unlink globally
|
||||
npm unlink -g @qwen-code/qwen-code
|
||||
|
||||
# Method 2: Remove it in the packages/cli directory
|
||||
cd packages/cli
|
||||
npm unlink
|
||||
|
||||
# Verification has been lifted
|
||||
which qwen
|
||||
# It should display "qwen not found"
|
||||
|
||||
# Reinstall the global version if necessary
|
||||
npm install -g @qwen-code/qwen-code
|
||||
|
||||
# Verification Recovery
|
||||
which qwen
|
||||
qwen --version
|
||||
```
|
||||
@@ -104,7 +104,7 @@ Settings are organized into categories. All settings should be placed within the
|
||||
| `model.name` | string | The Qwen model to use for conversations. | `undefined` |
|
||||
| `model.maxSessionTurns` | number | Maximum number of user/model/tool turns to keep in a session. -1 means unlimited. | `-1` |
|
||||
| `model.summarizeToolOutput` | object | Enables or disables the summarization of tool output. You can specify the token budget for the summarization using the `tokenBudget` setting. Note: Currently only the `run_shell_command` tool is supported. For example `{"run_shell_command": {"tokenBudget": 2000}}` | `undefined` |
|
||||
| `model.generationConfig` | object | Advanced overrides passed to the underlying content generator. Supports request controls such as `timeout`, `maxRetries`, and `disableCacheControl`, along with fine-tuning knobs under `samplingParams` (for example `temperature`, `top_p`, `max_tokens`). Leave unset to rely on provider defaults. | `undefined` |
|
||||
| `model.generationConfig` | object | Advanced overrides passed to the underlying content generator. Supports request controls such as `timeout`, `maxRetries`, `disableCacheControl`, and `customHeaders` (custom HTTP headers for API requests), along with fine-tuning knobs under `samplingParams` (for example `temperature`, `top_p`, `max_tokens`). Leave unset to rely on provider defaults. | `undefined` |
|
||||
| `model.chatCompression.contextPercentageThreshold` | number | Sets the threshold for chat history compression as a percentage of the model's total token limit. This is a value between 0 and 1 that applies to both automatic compression and the manual `/compress` command. For example, a value of `0.6` will trigger compression when the chat history exceeds 60% of the token limit. Use `0` to disable compression entirely. | `0.7` |
|
||||
| `model.skipNextSpeakerCheck` | boolean | Skip the next speaker check. | `false` |
|
||||
| `model.skipLoopDetection` | boolean | Disables loop detection checks. Loop detection prevents infinite loops in AI responses but can generate false positives that interrupt legitimate workflows. Enable this option if you experience frequent false positive loop detection interruptions. | `false` |
|
||||
@@ -114,12 +114,16 @@ Settings are organized into categories. All settings should be placed within the
|
||||
|
||||
**Example model.generationConfig:**
|
||||
|
||||
```
|
||||
```json
|
||||
{
|
||||
"model": {
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"disableCacheControl": false,
|
||||
"customHeaders": {
|
||||
"X-Request-ID": "req-123",
|
||||
"X-User-ID": "user-456"
|
||||
},
|
||||
"samplingParams": {
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
@@ -130,6 +134,8 @@ Settings are organized into categories. All settings should be placed within the
|
||||
}
|
||||
```
|
||||
|
||||
The `customHeaders` field allows you to add custom HTTP headers to all API requests. This is useful for request tracing, monitoring, API gateway routing, or when different models require different headers. If `customHeaders` is defined in `modelProviders[].generationConfig.customHeaders`, it will be used directly; otherwise, headers from `model.generationConfig.customHeaders` will be used. No merging occurs between the two levels.
|
||||
|
||||
**model.openAILoggingDir examples:**
|
||||
|
||||
- `"~/qwen-logs"` - Logs to `~/qwen-logs` directory
|
||||
@@ -154,6 +160,10 @@ Use `modelProviders` to declare curated model lists per auth type that the `/mod
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"maxRetries": 3,
|
||||
"customHeaders": {
|
||||
"X-Model-Version": "v1.0",
|
||||
"X-Request-Priority": "high"
|
||||
},
|
||||
"samplingParams": { "temperature": 0.2 }
|
||||
}
|
||||
}
|
||||
@@ -215,7 +225,7 @@ Per-field precedence for `generationConfig`:
|
||||
3. `settings.model.generationConfig`
|
||||
4. Content-generator defaults (`getDefaultGenerationConfig` for OpenAI, `getParameterValue` for Gemini, etc.)
|
||||
|
||||
`samplingParams` is treated atomically; provider values replace the entire object. Defaults from the content generator apply last so each provider retains its tuned baseline.
|
||||
`samplingParams` and `customHeaders` are both treated atomically; provider values replace the entire object. If `modelProviders[].generationConfig` defines these fields, they are used directly; otherwise, values from `model.generationConfig` are used. No merging occurs between provider and global configuration levels. Defaults from the content generator apply last so each provider retains its tuned baseline.
|
||||
|
||||
##### Selection persistence and recommendations
|
||||
|
||||
@@ -470,7 +480,7 @@ Arguments passed directly when running the CLI can override other configurations
|
||||
| `--telemetry-otlp-protocol` | | Sets the OTLP protocol for telemetry (`grpc` or `http`). | | Defaults to `grpc`. See [telemetry](../../developers/development/telemetry) for more information. |
|
||||
| `--telemetry-log-prompts` | | Enables logging of prompts for telemetry. | | See [telemetry](../../developers/development/telemetry) for more information. |
|
||||
| `--checkpointing` | | Enables [checkpointing](../features/checkpointing). | | |
|
||||
| `--acp` | | Enables ACP mode (Agent Control Protocol). Useful for IDE/editor integrations like [Zed](../integration-zed). | | Stable. Replaces the deprecated `--experimental-acp` flag. |
|
||||
| `--acp` | | Enables ACP mode (Agent Client Protocol). Useful for IDE/editor integrations like [Zed](../integration-zed). | | Stable. Replaces the deprecated `--experimental-acp` flag. |
|
||||
| `--experimental-skills` | | Enables experimental [Agent Skills](../features/skills) (registers the `skill` tool and loads Skills from `.qwen/skills/` and `~/.qwen/skills/`). | | Experimental. |
|
||||
| `--extensions` | `-e` | Specifies a list of extensions to use for the session. | Extension names | If not provided, all available extensions are used. Use the special term `qwen -e none` to disable all extensions. Example: `qwen -e my-extension -e my-other-extension` |
|
||||
| `--list-extensions` | `-l` | Lists all available extensions and exits. | | |
|
||||
|
||||
@@ -166,15 +166,6 @@ export SANDBOX_SET_UID_GID=true # Force host UID/GID
|
||||
export SANDBOX_SET_UID_GID=false # Disable UID/GID mapping
|
||||
```
|
||||
|
||||
## Customizing the sandbox environment (Docker/Podman)
|
||||
|
||||
If you need extra tools inside the container (e.g., `git`, `python`, `rg`), create a custom Dockerfile:
|
||||
|
||||
- Path: `.qwen/sandbox.Dockerfile`
|
||||
- Then run with: `BUILD_SANDBOX=1 qwen -s ...`
|
||||
|
||||
This builds a project-specific image based on the default sandbox image.
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Common issues
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 36 KiB |
@@ -1,11 +1,11 @@
|
||||
# JetBrains IDEs
|
||||
|
||||
> JetBrains IDEs provide native support for AI coding assistants through the Agent Control Protocol (ACP). This integration allows you to use Qwen Code directly within your JetBrains IDE with real-time code suggestions.
|
||||
> JetBrains IDEs provide native support for AI coding assistants through the Agent Client Protocol (ACP). This integration allows you to use Qwen Code directly within your JetBrains IDE with real-time code suggestions.
|
||||
|
||||
### Features
|
||||
|
||||
- **Native agent experience**: Integrated AI assistant panel within your JetBrains IDE
|
||||
- **Agent Control Protocol**: Full support for ACP enabling advanced IDE interactions
|
||||
- **Agent Client Protocol**: Full support for ACP enabling advanced IDE interactions
|
||||
- **Symbol management**: #-mention files to add them to the conversation context
|
||||
- **Conversation history**: Access to past conversations within the IDE
|
||||
|
||||
@@ -40,7 +40,7 @@
|
||||
|
||||
4. The Qwen Code agent should now be available in the AI Assistant panel
|
||||
|
||||

|
||||
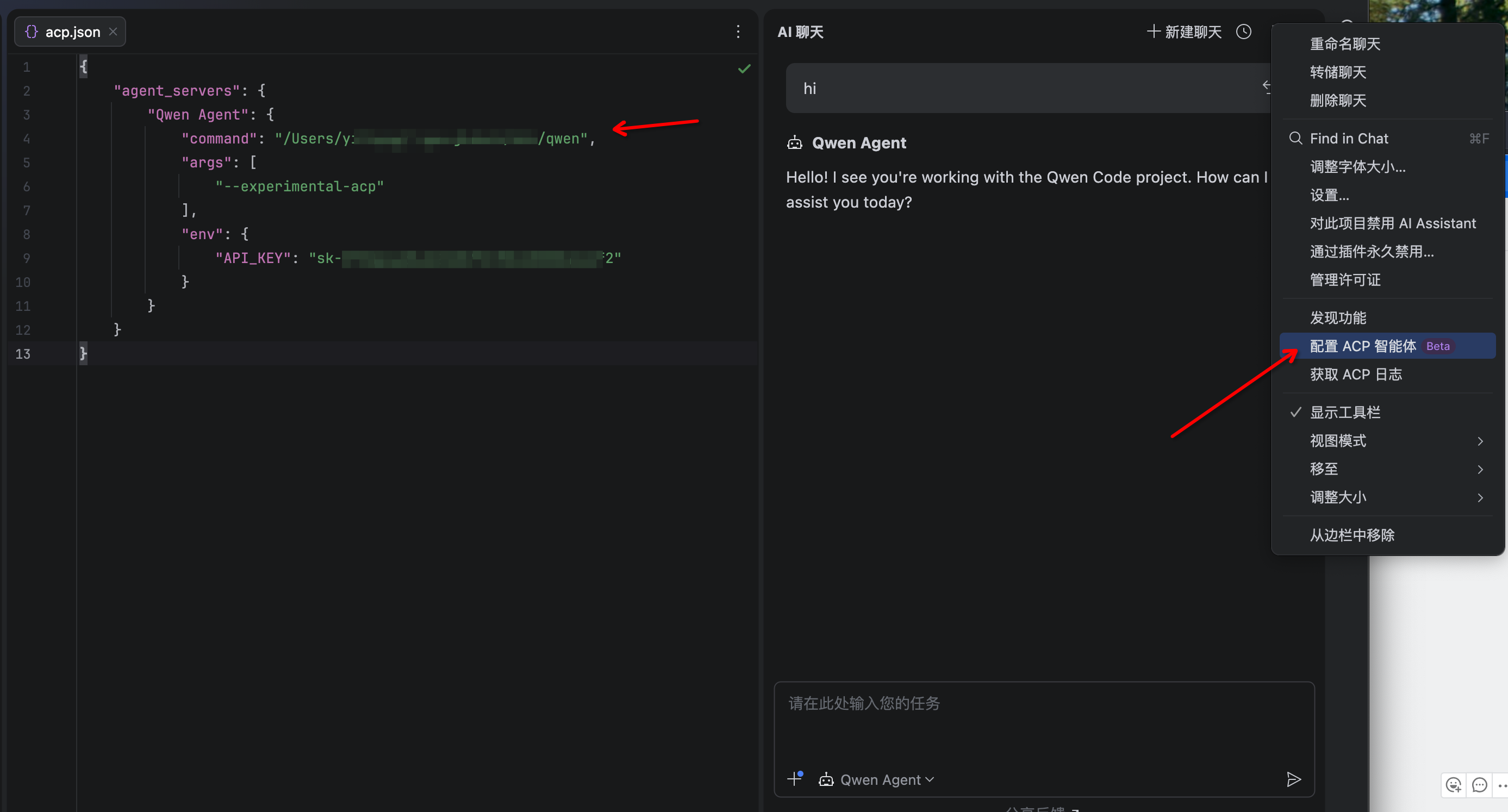
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
|
||||
@@ -22,13 +22,7 @@
|
||||
|
||||
### Installation
|
||||
|
||||
1. Install Qwen Code CLI:
|
||||
|
||||
```bash
|
||||
npm install -g qwen-code
|
||||
```
|
||||
|
||||
2. Download and install the extension from the [Visual Studio Code Extension Marketplace](https://marketplace.visualstudio.com/items?itemName=qwenlm.qwen-code-vscode-ide-companion).
|
||||
Download and install the extension from the [Visual Studio Code Extension Marketplace](https://marketplace.visualstudio.com/items?itemName=qwenlm.qwen-code-vscode-ide-companion).
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Zed Editor
|
||||
|
||||
> Zed Editor provides native support for AI coding assistants through the Agent Control Protocol (ACP). This integration allows you to use Qwen Code directly within Zed's interface with real-time code suggestions.
|
||||
> Zed Editor provides native support for AI coding assistants through the Agent Client Protocol (ACP). This integration allows you to use Qwen Code directly within Zed's interface with real-time code suggestions.
|
||||
|
||||
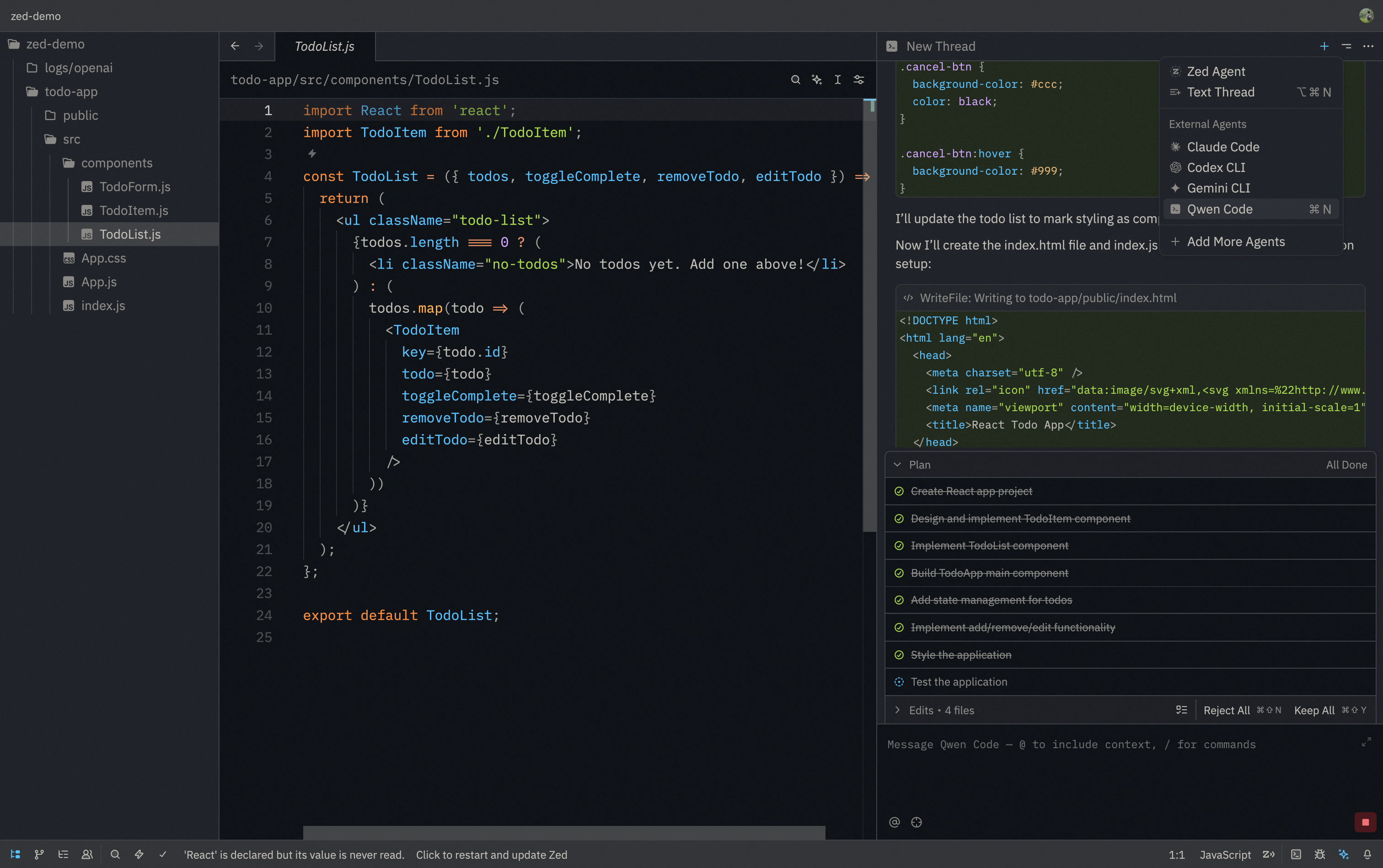
|
||||
|
||||
@@ -20,9 +20,9 @@
|
||||
|
||||
1. Install Qwen Code CLI:
|
||||
|
||||
```bash
|
||||
npm install -g qwen-code
|
||||
```
|
||||
```bash
|
||||
npm install -g @qwen-code/qwen-code
|
||||
```
|
||||
|
||||
2. Download and install [Zed Editor](https://zed.dev/)
|
||||
|
||||
|
||||
@@ -159,7 +159,7 @@ Qwen Code will:
|
||||
|
||||
### Test out other common workflows
|
||||
|
||||
There are a number of ways to work with Claude:
|
||||
There are a number of ways to work with Qwen Code:
|
||||
|
||||
**Refactor code**
|
||||
|
||||
|
||||
@@ -33,7 +33,6 @@ const external = [
|
||||
'@lydell/node-pty-linux-x64',
|
||||
'@lydell/node-pty-win32-arm64',
|
||||
'@lydell/node-pty-win32-x64',
|
||||
'tiktoken',
|
||||
];
|
||||
|
||||
esbuild
|
||||
|
||||
@@ -831,7 +831,7 @@ describe('Permission Control (E2E)', () => {
|
||||
TEST_TIMEOUT,
|
||||
);
|
||||
|
||||
it(
|
||||
it.skip(
|
||||
'should execute dangerous commands without confirmation',
|
||||
async () => {
|
||||
const q = query({
|
||||
|
||||
10
package-lock.json
generated
10
package-lock.json
generated
@@ -15682,12 +15682,6 @@
|
||||
"tslib": "^2"
|
||||
}
|
||||
},
|
||||
"node_modules/tiktoken": {
|
||||
"version": "1.0.22",
|
||||
"resolved": "https://registry.npmjs.org/tiktoken/-/tiktoken-1.0.22.tgz",
|
||||
"integrity": "sha512-PKvy1rVF1RibfF3JlXBSP0Jrcw2uq3yXdgcEXtKTYn3QJ/cBRBHDnrJ5jHky+MENZ6DIPwNUGWpkVx+7joCpNA==",
|
||||
"license": "MIT"
|
||||
},
|
||||
"node_modules/tinybench": {
|
||||
"version": "2.9.0",
|
||||
"resolved": "https://registry.npmjs.org/tinybench/-/tinybench-2.9.0.tgz",
|
||||
@@ -17990,7 +17984,6 @@
|
||||
"shell-quote": "^1.8.3",
|
||||
"simple-git": "^3.28.0",
|
||||
"strip-ansi": "^7.1.0",
|
||||
"tiktoken": "^1.0.21",
|
||||
"undici": "^6.22.0",
|
||||
"uuid": "^9.0.1",
|
||||
"ws": "^8.18.0"
|
||||
@@ -18588,11 +18581,10 @@
|
||||
},
|
||||
"packages/sdk-typescript": {
|
||||
"name": "@qwen-code/sdk",
|
||||
"version": "0.1.2",
|
||||
"version": "0.1.3",
|
||||
"license": "Apache-2.0",
|
||||
"dependencies": {
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"tiktoken": "^1.0.21",
|
||||
"zod": "^3.25.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
|
||||
@@ -38,14 +38,15 @@
|
||||
"dependencies": {
|
||||
"@google/genai": "1.30.0",
|
||||
"@iarna/toml": "^2.2.5",
|
||||
"@qwen-code/qwen-code-core": "file:../core",
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"@qwen-code/qwen-code-core": "file:../core",
|
||||
"@types/update-notifier": "^6.0.8",
|
||||
"ansi-regex": "^6.2.2",
|
||||
"command-exists": "^1.2.9",
|
||||
"comment-json": "^4.2.5",
|
||||
"diff": "^7.0.0",
|
||||
"dotenv": "^17.1.0",
|
||||
"extract-zip": "^2.0.1",
|
||||
"fzf": "^0.5.2",
|
||||
"glob": "^10.5.0",
|
||||
"highlight.js": "^11.11.1",
|
||||
@@ -65,7 +66,6 @@
|
||||
"strip-json-comments": "^3.1.1",
|
||||
"tar": "^7.5.2",
|
||||
"undici": "^6.22.0",
|
||||
"extract-zip": "^2.0.1",
|
||||
"update-notifier": "^7.3.1",
|
||||
"wrap-ansi": "9.0.2",
|
||||
"yargs": "^17.7.2",
|
||||
@@ -74,6 +74,7 @@
|
||||
"devDependencies": {
|
||||
"@babel/runtime": "^7.27.6",
|
||||
"@google/gemini-cli-test-utils": "file:../test-utils",
|
||||
"@qwen-code/qwen-code-test-utils": "file:../test-utils",
|
||||
"@testing-library/react": "^16.3.0",
|
||||
"@types/archiver": "^6.0.3",
|
||||
"@types/command-exists": "^1.2.3",
|
||||
@@ -92,8 +93,7 @@
|
||||
"pretty-format": "^30.0.2",
|
||||
"react-dom": "^19.1.0",
|
||||
"typescript": "^5.3.3",
|
||||
"vitest": "^3.1.1",
|
||||
"@qwen-code/qwen-code-test-utils": "file:../test-utils"
|
||||
"vitest": "^3.1.1"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=20"
|
||||
|
||||
@@ -83,12 +83,26 @@ export const useAuthCommand = (
|
||||
async (authType: AuthType, credentials?: OpenAICredentials) => {
|
||||
try {
|
||||
const authTypeScope = getPersistScopeForModelSelection(settings);
|
||||
|
||||
// Persist authType
|
||||
settings.setValue(
|
||||
authTypeScope,
|
||||
'security.auth.selectedType',
|
||||
authType,
|
||||
);
|
||||
|
||||
// Persist model from ContentGenerator config (handles fallback cases)
|
||||
// This ensures that when syncAfterAuthRefresh falls back to default model,
|
||||
// it gets persisted to settings.json
|
||||
const contentGeneratorConfig = config.getContentGeneratorConfig();
|
||||
if (contentGeneratorConfig?.model) {
|
||||
settings.setValue(
|
||||
authTypeScope,
|
||||
'model.name',
|
||||
contentGeneratorConfig.model,
|
||||
);
|
||||
}
|
||||
|
||||
// Only update credentials if not switching to QWEN_OAUTH,
|
||||
// so that OpenAI credentials are preserved when switching to QWEN_OAUTH.
|
||||
if (authType !== AuthType.QWEN_OAUTH && credentials) {
|
||||
@@ -106,9 +120,6 @@ export const useAuthCommand = (
|
||||
credentials.baseUrl,
|
||||
);
|
||||
}
|
||||
if (credentials?.model != null) {
|
||||
settings.setValue(authTypeScope, 'model.name', credentials.model);
|
||||
}
|
||||
}
|
||||
} catch (error) {
|
||||
handleAuthFailure(error);
|
||||
|
||||
@@ -117,8 +117,33 @@ describe('errors', () => {
|
||||
expect(getErrorMessage(undefined)).toBe('undefined');
|
||||
});
|
||||
|
||||
it('should handle objects', () => {
|
||||
const obj = { message: 'test' };
|
||||
it('should extract message from error-like objects', () => {
|
||||
const obj = { message: 'test error message' };
|
||||
expect(getErrorMessage(obj)).toBe('test error message');
|
||||
});
|
||||
|
||||
it('should stringify plain objects without message property', () => {
|
||||
const obj = { code: 500, details: 'internal error' };
|
||||
expect(getErrorMessage(obj)).toBe(
|
||||
'{"code":500,"details":"internal error"}',
|
||||
);
|
||||
});
|
||||
|
||||
it('should handle empty objects', () => {
|
||||
expect(getErrorMessage({})).toBe('{}');
|
||||
});
|
||||
|
||||
it('should handle objects with non-string message property', () => {
|
||||
const obj = { message: 123 };
|
||||
expect(getErrorMessage(obj)).toBe('{"message":123}');
|
||||
});
|
||||
|
||||
it('should fallback to String() when toJSON returns undefined', () => {
|
||||
const obj = {
|
||||
toJSON() {
|
||||
return undefined;
|
||||
},
|
||||
};
|
||||
expect(getErrorMessage(obj)).toBe('[object Object]');
|
||||
});
|
||||
});
|
||||
|
||||
@@ -18,6 +18,29 @@ export function getErrorMessage(error: unknown): string {
|
||||
if (error instanceof Error) {
|
||||
return error.message;
|
||||
}
|
||||
|
||||
// Handle objects with message property (error-like objects)
|
||||
if (
|
||||
error !== null &&
|
||||
typeof error === 'object' &&
|
||||
'message' in error &&
|
||||
typeof (error as { message: unknown }).message === 'string'
|
||||
) {
|
||||
return (error as { message: string }).message;
|
||||
}
|
||||
|
||||
// Handle plain objects by stringifying them
|
||||
if (error !== null && typeof error === 'object') {
|
||||
try {
|
||||
const stringified = JSON.stringify(error);
|
||||
// JSON.stringify can return undefined for objects with toJSON() returning undefined
|
||||
return stringified ?? String(error);
|
||||
} catch {
|
||||
// If JSON.stringify fails (circular reference, etc.), fall back to String
|
||||
return String(error);
|
||||
}
|
||||
}
|
||||
|
||||
return String(error);
|
||||
}
|
||||
|
||||
|
||||
@@ -10,6 +10,7 @@ import {
|
||||
type ContentGeneratorConfigSources,
|
||||
resolveModelConfig,
|
||||
type ModelConfigSourcesInput,
|
||||
type ProviderModelConfig,
|
||||
} from '@qwen-code/qwen-code-core';
|
||||
import type { Settings } from '../config/settings.js';
|
||||
|
||||
@@ -81,6 +82,21 @@ export function resolveCliGenerationConfig(
|
||||
|
||||
const authType = selectedAuthType;
|
||||
|
||||
// Find modelProvider from settings.modelProviders based on authType and model
|
||||
let modelProvider: ProviderModelConfig | undefined;
|
||||
if (authType && settings.modelProviders) {
|
||||
const providers = settings.modelProviders[authType];
|
||||
if (providers && Array.isArray(providers)) {
|
||||
// Try to find by requested model (from CLI or settings)
|
||||
const requestedModel = argv.model || settings.model?.name;
|
||||
if (requestedModel) {
|
||||
modelProvider = providers.find((p) => p.id === requestedModel) as
|
||||
| ProviderModelConfig
|
||||
| undefined;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const configSources: ModelConfigSourcesInput = {
|
||||
authType,
|
||||
cli: {
|
||||
@@ -96,6 +112,7 @@ export function resolveCliGenerationConfig(
|
||||
| Partial<ContentGeneratorConfig>
|
||||
| undefined,
|
||||
},
|
||||
modelProvider,
|
||||
env,
|
||||
};
|
||||
|
||||
@@ -103,7 +120,7 @@ export function resolveCliGenerationConfig(
|
||||
|
||||
// Log warnings if any
|
||||
for (const warning of resolved.warnings) {
|
||||
console.warn(`[modelProviderUtils] ${warning}`);
|
||||
console.warn(warning);
|
||||
}
|
||||
|
||||
// Resolve OpenAI logging config (CLI-specific, not part of core resolver)
|
||||
|
||||
@@ -360,10 +360,10 @@ export async function start_sandbox(
|
||||
//
|
||||
// note this can only be done with binary linked from gemini-cli repo
|
||||
if (process.env['BUILD_SANDBOX']) {
|
||||
if (!gcPath.includes('gemini-cli/packages/')) {
|
||||
if (!gcPath.includes('qwen-code/packages/')) {
|
||||
throw new FatalSandboxError(
|
||||
'Cannot build sandbox using installed gemini binary; ' +
|
||||
'run `npm link ./packages/cli` under gemini-cli repo to switch to linked binary.',
|
||||
'Cannot build sandbox using installed Qwen Code binary; ' +
|
||||
'run `npm link ./packages/cli` under QwenCode-cli repo to switch to linked binary.',
|
||||
);
|
||||
} else {
|
||||
console.error('building sandbox ...');
|
||||
|
||||
@@ -63,7 +63,6 @@
|
||||
"shell-quote": "^1.8.3",
|
||||
"simple-git": "^3.28.0",
|
||||
"strip-ansi": "^7.1.0",
|
||||
"tiktoken": "^1.0.21",
|
||||
"undici": "^6.22.0",
|
||||
"uuid": "^9.0.1",
|
||||
"ws": "^8.18.0"
|
||||
|
||||
@@ -10,6 +10,7 @@ import type {
|
||||
GenerateContentParameters,
|
||||
} from '@google/genai';
|
||||
import { FinishReason, GenerateContentResponse } from '@google/genai';
|
||||
import type { ContentGeneratorConfig } from '../contentGenerator.js';
|
||||
|
||||
// Mock the request tokenizer module BEFORE importing the class that uses it.
|
||||
const mockTokenizer = {
|
||||
@@ -18,9 +19,7 @@ const mockTokenizer = {
|
||||
};
|
||||
|
||||
vi.mock('../../utils/request-tokenizer/index.js', () => ({
|
||||
getDefaultTokenizer: vi.fn(() => mockTokenizer),
|
||||
DefaultRequestTokenizer: vi.fn(() => mockTokenizer),
|
||||
disposeDefaultTokenizer: vi.fn(),
|
||||
RequestTokenEstimator: vi.fn(() => mockTokenizer),
|
||||
}));
|
||||
|
||||
type AnthropicCreateArgs = [unknown, { signal?: AbortSignal }?];
|
||||
@@ -127,6 +126,32 @@ describe('AnthropicContentGenerator', () => {
|
||||
);
|
||||
});
|
||||
|
||||
it('merges customHeaders into defaultHeaders (does not replace defaults)', async () => {
|
||||
const { AnthropicContentGenerator } = await importGenerator();
|
||||
void new AnthropicContentGenerator(
|
||||
{
|
||||
model: 'claude-test',
|
||||
apiKey: 'test-key',
|
||||
baseUrl: 'https://example.invalid',
|
||||
timeout: 10_000,
|
||||
maxRetries: 2,
|
||||
samplingParams: {},
|
||||
schemaCompliance: 'auto',
|
||||
reasoning: { effort: 'medium' },
|
||||
customHeaders: {
|
||||
'X-Custom': '1',
|
||||
},
|
||||
} as unknown as Record<string, unknown> as ContentGeneratorConfig,
|
||||
mockConfig,
|
||||
);
|
||||
|
||||
const headers = (anthropicState.constructorOptions?.['defaultHeaders'] ||
|
||||
{}) as Record<string, string>;
|
||||
expect(headers['User-Agent']).toContain('QwenCode/1.2.3');
|
||||
expect(headers['anthropic-beta']).toContain('effort-2025-11-24');
|
||||
expect(headers['X-Custom']).toBe('1');
|
||||
});
|
||||
|
||||
it('adds the effort beta header when reasoning.effort is set', async () => {
|
||||
const { AnthropicContentGenerator } = await importGenerator();
|
||||
void new AnthropicContentGenerator(
|
||||
@@ -325,9 +350,7 @@ describe('AnthropicContentGenerator', () => {
|
||||
};
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
expect(mockTokenizer.calculateTokens).toHaveBeenCalledWith(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
expect(mockTokenizer.calculateTokens).toHaveBeenCalledWith(request);
|
||||
expect(result.totalTokens).toBe(50);
|
||||
});
|
||||
|
||||
|
||||
@@ -25,7 +25,7 @@ type MessageCreateParamsNonStreaming =
|
||||
Anthropic.MessageCreateParamsNonStreaming;
|
||||
type MessageCreateParamsStreaming = Anthropic.MessageCreateParamsStreaming;
|
||||
type RawMessageStreamEvent = Anthropic.RawMessageStreamEvent;
|
||||
import { getDefaultTokenizer } from '../../utils/request-tokenizer/index.js';
|
||||
import { RequestTokenEstimator } from '../../utils/request-tokenizer/index.js';
|
||||
import { safeJsonParse } from '../../utils/safeJsonParse.js';
|
||||
import { AnthropicContentConverter } from './converter.js';
|
||||
|
||||
@@ -105,10 +105,8 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
request: CountTokensParameters,
|
||||
): Promise<CountTokensResponse> {
|
||||
try {
|
||||
const tokenizer = getDefaultTokenizer();
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
const estimator = new RequestTokenEstimator();
|
||||
const result = await estimator.calculateTokens(request);
|
||||
|
||||
return {
|
||||
totalTokens: result.totalTokens,
|
||||
@@ -141,6 +139,7 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
private buildHeaders(): Record<string, string> {
|
||||
const version = this.cliConfig.getCliVersion() || 'unknown';
|
||||
const userAgent = `QwenCode/${version} (${process.platform}; ${process.arch})`;
|
||||
const { customHeaders } = this.contentGeneratorConfig;
|
||||
|
||||
const betas: string[] = [];
|
||||
const reasoning = this.contentGeneratorConfig.reasoning;
|
||||
@@ -163,7 +162,7 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
headers['anthropic-beta'] = betas.join(',');
|
||||
}
|
||||
|
||||
return headers;
|
||||
return customHeaders ? { ...headers, ...customHeaders } : headers;
|
||||
}
|
||||
|
||||
private async buildRequest(
|
||||
|
||||
@@ -153,6 +153,26 @@ vi.mock('../telemetry/loggers.js', () => ({
|
||||
logNextSpeakerCheck: vi.fn(),
|
||||
}));
|
||||
|
||||
// Mock RequestTokenizer to use simple character-based estimation
|
||||
vi.mock('../utils/request-tokenizer/requestTokenizer.js', () => ({
|
||||
RequestTokenizer: class {
|
||||
async calculateTokens(request: { contents: unknown }) {
|
||||
// Simple estimation: count characters in JSON and divide by 4
|
||||
const totalChars = JSON.stringify(request.contents).length;
|
||||
return {
|
||||
totalTokens: Math.floor(totalChars / 4),
|
||||
breakdown: {
|
||||
textTokens: Math.floor(totalChars / 4),
|
||||
imageTokens: 0,
|
||||
audioTokens: 0,
|
||||
otherTokens: 0,
|
||||
},
|
||||
processingTime: 0,
|
||||
};
|
||||
}
|
||||
},
|
||||
}));
|
||||
|
||||
/**
|
||||
* Array.fromAsync ponyfill, which will be available in es 2024.
|
||||
*
|
||||
@@ -417,6 +437,12 @@ describe('Gemini Client (client.ts)', () => {
|
||||
] as Content[],
|
||||
originalTokenCount = 1000,
|
||||
summaryText = 'This is a summary.',
|
||||
// Token counts returned in usageMetadata to simulate what the API would return
|
||||
// Default values ensure successful compression:
|
||||
// newTokenCount = originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
// = 1000 - (1600 - 1000) + 50 = 1000 - 600 + 50 = 450 (< 1000, success)
|
||||
compressionInputTokenCount = 1600,
|
||||
compressionOutputTokenCount = 50,
|
||||
} = {}) {
|
||||
const mockOriginalChat: Partial<GeminiChat> = {
|
||||
getHistory: vi.fn((_curated?: boolean) => chatHistory),
|
||||
@@ -438,6 +464,12 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: compressionInputTokenCount,
|
||||
candidatesTokenCount: compressionOutputTokenCount,
|
||||
totalTokenCount:
|
||||
compressionInputTokenCount + compressionOutputTokenCount,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
// Calculate what the new history will be
|
||||
@@ -477,11 +509,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
// New token count formula: originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
const estimatedNewTokenCount = Math.max(
|
||||
0,
|
||||
originalTokenCount -
|
||||
(compressionInputTokenCount - 1000) +
|
||||
compressionOutputTokenCount,
|
||||
);
|
||||
const estimatedNewTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
return {
|
||||
client,
|
||||
@@ -493,49 +527,58 @@ describe('Gemini Client (client.ts)', () => {
|
||||
|
||||
describe('when compression inflates the token count', () => {
|
||||
it('allows compression to be forced/manual after a failure', async () => {
|
||||
// Call 1 (Fails): Setup with a long summary to inflate tokens
|
||||
// Call 1 (Fails): Setup with token counts that will inflate
|
||||
// newTokenCount = originalTokenCount - (compressionInputTokenCount - 1000) + compressionOutputTokenCount
|
||||
// = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount: inflatedTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(inflatedTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
await client.tryCompressChat('prompt-id-4', false); // Fails
|
||||
|
||||
// Call 2 (Forced): Re-setup with a short summary
|
||||
// Call 2 (Forced): Re-setup with token counts that will compress
|
||||
// newTokenCount = 100 - (1100 - 1000) + 50 = 100 - 100 + 50 = 50 <= 100 (compression)
|
||||
const shortSummary = 'short';
|
||||
const { estimatedNewTokenCount: compressedTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: shortSummary,
|
||||
compressionInputTokenCount: 1100,
|
||||
compressionOutputTokenCount: 50,
|
||||
});
|
||||
expect(compressedTokenCount).toBeLessThanOrEqual(100); // Ensure setup is correct
|
||||
|
||||
const result = await client.tryCompressChat('prompt-id-4', true); // Forced
|
||||
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
newTokenCount: compressedTokenCount,
|
||||
originalTokenCount: 100,
|
||||
});
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(100);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(100);
|
||||
});
|
||||
|
||||
it('yields the result even if the compression inflated the tokens', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
const result = await client.tryCompressChat('prompt-id-4', false);
|
||||
|
||||
expect(result).toEqual({
|
||||
compressionStatus:
|
||||
CompressionStatus.COMPRESSION_FAILED_INFLATED_TOKEN_COUNT,
|
||||
newTokenCount: estimatedNewTokenCount,
|
||||
originalTokenCount: 100,
|
||||
});
|
||||
expect(result.compressionStatus).toBe(
|
||||
CompressionStatus.COMPRESSION_FAILED_INFLATED_TOKEN_COUNT,
|
||||
);
|
||||
expect(result.originalTokenCount).toBe(100);
|
||||
// The newTokenCount should be higher than original since compression failed due to inflation
|
||||
expect(result.newTokenCount).toBeGreaterThan(100);
|
||||
// IMPORTANT: The change in client.ts means setLastPromptTokenCount is NOT called on failure
|
||||
expect(
|
||||
uiTelemetryService.setLastPromptTokenCount,
|
||||
@@ -543,10 +586,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
});
|
||||
|
||||
it('does not manipulate the source chat', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, mockOriginalChat, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
@@ -557,10 +603,13 @@ describe('Gemini Client (client.ts)', () => {
|
||||
});
|
||||
|
||||
it('will not attempt to compress context after a failure', async () => {
|
||||
// newTokenCount = 100 - (1010 - 1000) + 200 = 100 - 10 + 200 = 290 > 100 (inflation)
|
||||
const longSummary = 'long summary '.repeat(100);
|
||||
const { client, estimatedNewTokenCount } = setup({
|
||||
originalTokenCount: 100,
|
||||
summaryText: longSummary,
|
||||
compressionInputTokenCount: 1010,
|
||||
compressionOutputTokenCount: 200,
|
||||
});
|
||||
expect(estimatedNewTokenCount).toBeGreaterThan(100); // Ensure setup is correct
|
||||
|
||||
@@ -631,6 +680,7 @@ describe('Gemini Client (client.ts)', () => {
|
||||
);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 501 - (1400 - 1000) + 50 = 501 - 400 + 50 = 151 <= 501 (success)
|
||||
const summaryText = 'This is a summary.';
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
@@ -641,6 +691,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1400,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1450,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
// Mock startChat to complete the compression flow
|
||||
@@ -719,13 +774,8 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 501 - (1400 - 1000) + 50 = 501 - 400 + 50 = 151 <= 501 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -735,6 +785,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1400,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1450,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -744,12 +799,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
expect(tokenLimit).toHaveBeenCalled();
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
// Assert that summarization happened and returned the correct stats
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
// Assert that summarization happened
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
@@ -809,13 +863,8 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 700 - (1500 - 1000) + 50 = 700 - 500 + 50 = 250 <= 700 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -825,6 +874,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1500,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1550,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -834,12 +888,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
expect(tokenLimit).toHaveBeenCalled();
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
// Assert that summarization happened and returned the correct stats
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
// Assert that summarization happened
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
|
||||
@@ -887,13 +940,8 @@ describe('Gemini Client (client.ts)', () => {
|
||||
.fn()
|
||||
.mockResolvedValue(mockNewChat as GeminiChat);
|
||||
|
||||
const totalChars = newCompressedHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
0,
|
||||
);
|
||||
const newTokenCount = Math.floor(totalChars / 4);
|
||||
|
||||
// Mock the summary response from the chat
|
||||
// newTokenCount = 100 - (1060 - 1000) + 20 = 100 - 60 + 20 = 60 <= 100 (success)
|
||||
mockGenerateContentFn.mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -903,6 +951,11 @@ describe('Gemini Client (client.ts)', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1060,
|
||||
candidatesTokenCount: 20,
|
||||
totalTokenCount: 1080,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
|
||||
const initialChat = client.getChat();
|
||||
@@ -911,11 +964,10 @@ describe('Gemini Client (client.ts)', () => {
|
||||
|
||||
expect(mockGenerateContentFn).toHaveBeenCalled();
|
||||
|
||||
expect(result).toEqual({
|
||||
compressionStatus: CompressionStatus.COMPRESSED,
|
||||
originalTokenCount,
|
||||
newTokenCount,
|
||||
});
|
||||
expect(result.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.originalTokenCount).toBe(originalTokenCount);
|
||||
// newTokenCount might be clamped to originalTokenCount due to tolerance logic
|
||||
expect(result.newTokenCount).toBeLessThanOrEqual(originalTokenCount);
|
||||
|
||||
// Assert that the chat was reset
|
||||
expect(newChat).not.toBe(initialChat);
|
||||
|
||||
@@ -441,47 +441,19 @@ export class GeminiClient {
|
||||
yield { type: GeminiEventType.ChatCompressed, value: compressed };
|
||||
}
|
||||
|
||||
// Check session token limit after compression using accurate token counting
|
||||
// Check session token limit after compression.
|
||||
// `lastPromptTokenCount` is treated as authoritative for the (possibly compressed) history;
|
||||
const sessionTokenLimit = this.config.getSessionTokenLimit();
|
||||
if (sessionTokenLimit > 0) {
|
||||
// Get all the content that would be sent in an API call
|
||||
const currentHistory = this.getChat().getHistory(true);
|
||||
const userMemory = this.config.getUserMemory();
|
||||
const systemPrompt = getCoreSystemPrompt(
|
||||
userMemory,
|
||||
this.config.getModel(),
|
||||
);
|
||||
const initialHistory = await getInitialChatHistory(this.config);
|
||||
|
||||
// Create a mock request content to count total tokens
|
||||
const mockRequestContent = [
|
||||
{
|
||||
role: 'system' as const,
|
||||
parts: [{ text: systemPrompt }],
|
||||
},
|
||||
...initialHistory,
|
||||
...currentHistory,
|
||||
];
|
||||
|
||||
// Use the improved countTokens method for accurate counting
|
||||
const { totalTokens: totalRequestTokens } = await this.config
|
||||
.getContentGenerator()
|
||||
.countTokens({
|
||||
model: this.config.getModel(),
|
||||
contents: mockRequestContent,
|
||||
});
|
||||
|
||||
if (
|
||||
totalRequestTokens !== undefined &&
|
||||
totalRequestTokens > sessionTokenLimit
|
||||
) {
|
||||
const lastPromptTokenCount = uiTelemetryService.getLastPromptTokenCount();
|
||||
if (lastPromptTokenCount > sessionTokenLimit) {
|
||||
yield {
|
||||
type: GeminiEventType.SessionTokenLimitExceeded,
|
||||
value: {
|
||||
currentTokens: totalRequestTokens,
|
||||
currentTokens: lastPromptTokenCount,
|
||||
limit: sessionTokenLimit,
|
||||
message:
|
||||
`Session token limit exceeded: ${totalRequestTokens} tokens > ${sessionTokenLimit} limit. ` +
|
||||
`Session token limit exceeded: ${lastPromptTokenCount} tokens > ${sessionTokenLimit} limit. ` +
|
||||
'Please start a new session or increase the sessionTokenLimit in your settings.json.',
|
||||
},
|
||||
};
|
||||
|
||||
@@ -91,6 +91,8 @@ export type ContentGeneratorConfig = {
|
||||
userAgent?: string;
|
||||
// Schema compliance mode for tool definitions
|
||||
schemaCompliance?: 'auto' | 'openapi_30';
|
||||
// Custom HTTP headers to be sent with requests
|
||||
customHeaders?: Record<string, string>;
|
||||
};
|
||||
|
||||
// Keep the public ContentGeneratorConfigSources API, but reuse the generic
|
||||
|
||||
@@ -708,7 +708,7 @@ describe('GeminiChat', () => {
|
||||
|
||||
// Verify that token counting is called when usageMetadata is present
|
||||
expect(uiTelemetryService.setLastPromptTokenCount).toHaveBeenCalledWith(
|
||||
42,
|
||||
57,
|
||||
);
|
||||
expect(uiTelemetryService.setLastPromptTokenCount).toHaveBeenCalledTimes(
|
||||
1,
|
||||
|
||||
@@ -529,10 +529,10 @@ export class GeminiChat {
|
||||
// Collect token usage for consolidated recording
|
||||
if (chunk.usageMetadata) {
|
||||
usageMetadata = chunk.usageMetadata;
|
||||
if (chunk.usageMetadata.promptTokenCount !== undefined) {
|
||||
uiTelemetryService.setLastPromptTokenCount(
|
||||
chunk.usageMetadata.promptTokenCount,
|
||||
);
|
||||
const lastPromptTokenCount =
|
||||
usageMetadata.totalTokenCount ?? usageMetadata.promptTokenCount;
|
||||
if (lastPromptTokenCount) {
|
||||
uiTelemetryService.setLastPromptTokenCount(lastPromptTokenCount);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -39,6 +39,41 @@ describe('GeminiContentGenerator', () => {
|
||||
mockGoogleGenAI = vi.mocked(GoogleGenAI).mock.results[0].value;
|
||||
});
|
||||
|
||||
it('should merge customHeaders into existing httpOptions.headers', async () => {
|
||||
vi.mocked(GoogleGenAI).mockClear();
|
||||
|
||||
void new GeminiContentGenerator(
|
||||
{
|
||||
apiKey: 'test-api-key',
|
||||
httpOptions: {
|
||||
headers: {
|
||||
'X-Base': 'base',
|
||||
'X-Override': 'base',
|
||||
},
|
||||
},
|
||||
},
|
||||
{
|
||||
customHeaders: {
|
||||
'X-Custom': 'custom',
|
||||
'X-Override': 'custom',
|
||||
},
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
} as any,
|
||||
);
|
||||
|
||||
expect(vi.mocked(GoogleGenAI)).toHaveBeenCalledTimes(1);
|
||||
expect(vi.mocked(GoogleGenAI)).toHaveBeenCalledWith({
|
||||
apiKey: 'test-api-key',
|
||||
httpOptions: {
|
||||
headers: {
|
||||
'X-Base': 'base',
|
||||
'X-Custom': 'custom',
|
||||
'X-Override': 'custom',
|
||||
},
|
||||
},
|
||||
});
|
||||
});
|
||||
|
||||
it('should call generateContent on the underlying model', async () => {
|
||||
const request = { model: 'gemini-1.5-flash', contents: [] };
|
||||
const expectedResponse = { responseId: 'test-id' };
|
||||
|
||||
@@ -35,7 +35,26 @@ export class GeminiContentGenerator implements ContentGenerator {
|
||||
},
|
||||
contentGeneratorConfig?: ContentGeneratorConfig,
|
||||
) {
|
||||
this.googleGenAI = new GoogleGenAI(options);
|
||||
const customHeaders = contentGeneratorConfig?.customHeaders;
|
||||
const finalOptions = customHeaders
|
||||
? (() => {
|
||||
const baseHttpOptions = options.httpOptions;
|
||||
const baseHeaders = baseHttpOptions?.headers ?? {};
|
||||
|
||||
return {
|
||||
...options,
|
||||
httpOptions: {
|
||||
...(baseHttpOptions ?? {}),
|
||||
headers: {
|
||||
...baseHeaders,
|
||||
...customHeaders,
|
||||
},
|
||||
},
|
||||
};
|
||||
})()
|
||||
: options;
|
||||
|
||||
this.googleGenAI = new GoogleGenAI(finalOptions);
|
||||
this.contentGeneratorConfig = contentGeneratorConfig;
|
||||
}
|
||||
|
||||
|
||||
@@ -22,17 +22,7 @@ const mockTokenizer = {
|
||||
};
|
||||
|
||||
vi.mock('../../../utils/request-tokenizer/index.js', () => ({
|
||||
getDefaultTokenizer: vi.fn(() => mockTokenizer),
|
||||
DefaultRequestTokenizer: vi.fn(() => mockTokenizer),
|
||||
disposeDefaultTokenizer: vi.fn(),
|
||||
}));
|
||||
|
||||
// Mock tiktoken as well for completeness
|
||||
vi.mock('tiktoken', () => ({
|
||||
get_encoding: vi.fn(() => ({
|
||||
encode: vi.fn(() => new Array(50)), // Mock 50 tokens
|
||||
free: vi.fn(),
|
||||
})),
|
||||
RequestTokenEstimator: vi.fn(() => mockTokenizer),
|
||||
}));
|
||||
|
||||
// Now import the modules that depend on the mocked modules
|
||||
@@ -134,7 +124,7 @@ describe('OpenAIContentGenerator (Refactored)', () => {
|
||||
});
|
||||
|
||||
describe('countTokens', () => {
|
||||
it('should count tokens using tiktoken', async () => {
|
||||
it('should count tokens using character-based estimation', async () => {
|
||||
const request: CountTokensParameters = {
|
||||
contents: [{ role: 'user', parts: [{ text: 'Hello world' }] }],
|
||||
model: 'gpt-4',
|
||||
@@ -142,26 +132,27 @@ describe('OpenAIContentGenerator (Refactored)', () => {
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
|
||||
expect(result.totalTokens).toBe(50); // Mocked value
|
||||
// 'Hello world' = 11 ASCII chars
|
||||
// 11 / 4 = 2.75 -> ceil = 3 tokens
|
||||
expect(result.totalTokens).toBe(3);
|
||||
});
|
||||
|
||||
it('should fall back to character approximation if tiktoken fails', async () => {
|
||||
// Mock tiktoken to throw error
|
||||
vi.doMock('tiktoken', () => ({
|
||||
get_encoding: vi.fn().mockImplementation(() => {
|
||||
throw new Error('Tiktoken failed');
|
||||
}),
|
||||
}));
|
||||
|
||||
it('should handle multimodal content', async () => {
|
||||
const request: CountTokensParameters = {
|
||||
contents: [{ role: 'user', parts: [{ text: 'Hello world' }] }],
|
||||
contents: [
|
||||
{
|
||||
role: 'user',
|
||||
parts: [{ text: 'Hello' }, { text: ' world' }],
|
||||
},
|
||||
],
|
||||
model: 'gpt-4',
|
||||
};
|
||||
|
||||
const result = await generator.countTokens(request);
|
||||
|
||||
// Should use character approximation (content length / 4)
|
||||
expect(result.totalTokens).toBeGreaterThan(0);
|
||||
// Parts are combined for estimation:
|
||||
// 'Hello world' = 11 ASCII chars -> 11/4 = 2.75 -> ceil = 3 tokens
|
||||
expect(result.totalTokens).toBe(3);
|
||||
});
|
||||
});
|
||||
|
||||
|
||||
@@ -12,7 +12,7 @@ import type {
|
||||
import type { PipelineConfig } from './pipeline.js';
|
||||
import { ContentGenerationPipeline } from './pipeline.js';
|
||||
import { EnhancedErrorHandler } from './errorHandler.js';
|
||||
import { getDefaultTokenizer } from '../../utils/request-tokenizer/index.js';
|
||||
import { RequestTokenEstimator } from '../../utils/request-tokenizer/index.js';
|
||||
import type { ContentGeneratorConfig } from '../contentGenerator.js';
|
||||
|
||||
export class OpenAIContentGenerator implements ContentGenerator {
|
||||
@@ -68,11 +68,9 @@ export class OpenAIContentGenerator implements ContentGenerator {
|
||||
request: CountTokensParameters,
|
||||
): Promise<CountTokensResponse> {
|
||||
try {
|
||||
// Use the new high-performance request tokenizer
|
||||
const tokenizer = getDefaultTokenizer();
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base', // Use GPT-4 encoding for consistency
|
||||
});
|
||||
// Use the request token estimator (character-based).
|
||||
const estimator = new RequestTokenEstimator();
|
||||
const result = await estimator.calculateTokens(request);
|
||||
|
||||
return {
|
||||
totalTokens: result.totalTokens,
|
||||
|
||||
@@ -142,6 +142,27 @@ describe('DashScopeOpenAICompatibleProvider', () => {
|
||||
});
|
||||
});
|
||||
|
||||
it('should merge custom headers with DashScope defaults', () => {
|
||||
const providerWithCustomHeaders = new DashScopeOpenAICompatibleProvider(
|
||||
{
|
||||
...mockContentGeneratorConfig,
|
||||
customHeaders: {
|
||||
'X-Custom': '1',
|
||||
'X-DashScope-CacheControl': 'disable',
|
||||
},
|
||||
} as ContentGeneratorConfig,
|
||||
mockCliConfig,
|
||||
);
|
||||
|
||||
const headers = providerWithCustomHeaders.buildHeaders();
|
||||
|
||||
expect(headers['User-Agent']).toContain('QwenCode/1.0.0');
|
||||
expect(headers['X-DashScope-UserAgent']).toContain('QwenCode/1.0.0');
|
||||
expect(headers['X-DashScope-AuthType']).toBe(AuthType.QWEN_OAUTH);
|
||||
expect(headers['X-Custom']).toBe('1');
|
||||
expect(headers['X-DashScope-CacheControl']).toBe('disable');
|
||||
});
|
||||
|
||||
it('should handle unknown CLI version', () => {
|
||||
(
|
||||
mockCliConfig.getCliVersion as MockedFunction<
|
||||
|
||||
@@ -47,13 +47,17 @@ export class DashScopeOpenAICompatibleProvider
|
||||
buildHeaders(): Record<string, string | undefined> {
|
||||
const version = this.cliConfig.getCliVersion() || 'unknown';
|
||||
const userAgent = `QwenCode/${version} (${process.platform}; ${process.arch})`;
|
||||
const { authType } = this.contentGeneratorConfig;
|
||||
return {
|
||||
const { authType, customHeaders } = this.contentGeneratorConfig;
|
||||
const defaultHeaders = {
|
||||
'User-Agent': userAgent,
|
||||
'X-DashScope-CacheControl': 'enable',
|
||||
'X-DashScope-UserAgent': userAgent,
|
||||
'X-DashScope-AuthType': authType,
|
||||
};
|
||||
|
||||
return customHeaders
|
||||
? { ...defaultHeaders, ...customHeaders }
|
||||
: defaultHeaders;
|
||||
}
|
||||
|
||||
buildClient(): OpenAI {
|
||||
|
||||
@@ -73,6 +73,26 @@ describe('DefaultOpenAICompatibleProvider', () => {
|
||||
});
|
||||
});
|
||||
|
||||
it('should merge customHeaders with defaults (and allow overrides)', () => {
|
||||
const providerWithCustomHeaders = new DefaultOpenAICompatibleProvider(
|
||||
{
|
||||
...mockContentGeneratorConfig,
|
||||
customHeaders: {
|
||||
'X-Custom': '1',
|
||||
'User-Agent': 'custom-agent',
|
||||
},
|
||||
} as ContentGeneratorConfig,
|
||||
mockCliConfig,
|
||||
);
|
||||
|
||||
const headers = providerWithCustomHeaders.buildHeaders();
|
||||
|
||||
expect(headers).toEqual({
|
||||
'User-Agent': 'custom-agent',
|
||||
'X-Custom': '1',
|
||||
});
|
||||
});
|
||||
|
||||
it('should handle unknown CLI version', () => {
|
||||
(
|
||||
mockCliConfig.getCliVersion as MockedFunction<
|
||||
|
||||
@@ -25,9 +25,14 @@ export class DefaultOpenAICompatibleProvider
|
||||
buildHeaders(): Record<string, string | undefined> {
|
||||
const version = this.cliConfig.getCliVersion() || 'unknown';
|
||||
const userAgent = `QwenCode/${version} (${process.platform}; ${process.arch})`;
|
||||
return {
|
||||
const { customHeaders } = this.contentGeneratorConfig;
|
||||
const defaultHeaders = {
|
||||
'User-Agent': userAgent,
|
||||
};
|
||||
|
||||
return customHeaders
|
||||
? { ...defaultHeaders, ...customHeaders }
|
||||
: defaultHeaders;
|
||||
}
|
||||
|
||||
buildClient(): OpenAI {
|
||||
|
||||
@@ -25,6 +25,7 @@ export const MODEL_GENERATION_CONFIG_FIELDS = [
|
||||
'disableCacheControl',
|
||||
'schemaCompliance',
|
||||
'reasoning',
|
||||
'customHeaders',
|
||||
] as const satisfies ReadonlyArray<keyof ContentGeneratorConfig>;
|
||||
|
||||
/**
|
||||
@@ -105,15 +106,6 @@ export const QWEN_OAUTH_MODELS: ModelConfig[] = [
|
||||
description:
|
||||
'The latest Qwen Coder model from Alibaba Cloud ModelStudio (version: qwen3-coder-plus-2025-09-23)',
|
||||
capabilities: { vision: false },
|
||||
generationConfig: {
|
||||
samplingParams: {
|
||||
temperature: 0.7,
|
||||
top_p: 0.9,
|
||||
max_tokens: 8192,
|
||||
},
|
||||
timeout: 60000,
|
||||
maxRetries: 3,
|
||||
},
|
||||
},
|
||||
{
|
||||
id: 'vision-model',
|
||||
@@ -121,14 +113,5 @@ export const QWEN_OAUTH_MODELS: ModelConfig[] = [
|
||||
description:
|
||||
'The latest Qwen Vision model from Alibaba Cloud ModelStudio (version: qwen3-vl-plus-2025-09-23)',
|
||||
capabilities: { vision: true },
|
||||
generationConfig: {
|
||||
samplingParams: {
|
||||
temperature: 0.7,
|
||||
top_p: 0.9,
|
||||
max_tokens: 8192,
|
||||
},
|
||||
timeout: 60000,
|
||||
maxRetries: 3,
|
||||
},
|
||||
},
|
||||
];
|
||||
|
||||
@@ -112,11 +112,9 @@ describe('modelConfigResolver', () => {
|
||||
modelProvider: {
|
||||
id: 'provider-model',
|
||||
name: 'Provider Model',
|
||||
authType: AuthType.USE_OPENAI,
|
||||
envKey: 'MY_CUSTOM_KEY',
|
||||
baseUrl: 'https://provider.example.com',
|
||||
generationConfig: {},
|
||||
capabilities: {},
|
||||
},
|
||||
});
|
||||
|
||||
@@ -249,13 +247,11 @@ describe('modelConfigResolver', () => {
|
||||
modelProvider: {
|
||||
id: 'model',
|
||||
name: 'Model',
|
||||
authType: AuthType.USE_OPENAI,
|
||||
envKey: 'MY_KEY',
|
||||
baseUrl: 'https://api.example.com',
|
||||
generationConfig: {
|
||||
timeout: 60000,
|
||||
},
|
||||
capabilities: {},
|
||||
},
|
||||
});
|
||||
|
||||
|
||||
@@ -41,7 +41,7 @@ import {
|
||||
QWEN_OAUTH_ALLOWED_MODELS,
|
||||
MODEL_GENERATION_CONFIG_FIELDS,
|
||||
} from './constants.js';
|
||||
import type { ResolvedModelConfig } from './types.js';
|
||||
import type { ModelConfig as ModelProviderConfig } from './types.js';
|
||||
export {
|
||||
validateModelConfig,
|
||||
type ModelConfigValidationResult,
|
||||
@@ -86,8 +86,8 @@ export interface ModelConfigSourcesInput {
|
||||
/** Environment variables (injected for testability) */
|
||||
env: Record<string, string | undefined>;
|
||||
|
||||
/** Resolved model from ModelProviders (explicit selection, highest priority) */
|
||||
modelProvider?: ResolvedModelConfig;
|
||||
/** Model from ModelProviders (explicit selection, highest priority) */
|
||||
modelProvider?: ModelProviderConfig;
|
||||
|
||||
/** Proxy URL (computed from Config) */
|
||||
proxy?: string;
|
||||
@@ -277,7 +277,7 @@ function resolveQwenOAuthConfig(
|
||||
input: ModelConfigSourcesInput,
|
||||
warnings: string[],
|
||||
): ModelConfigResolutionResult {
|
||||
const { cli, settings, proxy } = input;
|
||||
const { cli, settings, proxy, modelProvider } = input;
|
||||
const sources: ConfigSources = {};
|
||||
|
||||
// Qwen OAuth only allows specific models
|
||||
@@ -311,10 +311,10 @@ function resolveQwenOAuthConfig(
|
||||
sources['proxy'] = computedSource('Config.getProxy()');
|
||||
}
|
||||
|
||||
// Resolve generation config from settings
|
||||
// Resolve generation config from settings and modelProvider
|
||||
const generationConfig = resolveGenerationConfig(
|
||||
settings?.generationConfig,
|
||||
undefined,
|
||||
modelProvider?.generationConfig,
|
||||
AuthType.QWEN_OAUTH,
|
||||
resolvedModel,
|
||||
sources,
|
||||
@@ -344,7 +344,7 @@ function resolveGenerationConfig(
|
||||
const result: Partial<ContentGeneratorConfig> = {};
|
||||
|
||||
for (const field of MODEL_GENERATION_CONFIG_FIELDS) {
|
||||
// ModelProvider config takes priority
|
||||
// ModelProvider config takes priority over settings config
|
||||
if (authType && modelProviderConfig && field in modelProviderConfig) {
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
(result as any)[field] = modelProviderConfig[field];
|
||||
|
||||
@@ -480,6 +480,91 @@ describe('ModelsConfig', () => {
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should use default model for new authType when switching from different authType with env vars', () => {
|
||||
// Simulate cold start with OPENAI env vars (OPENAI_MODEL and OPENAI_API_KEY)
|
||||
// This sets the model in generationConfig but no authType is selected yet
|
||||
const modelsConfig = new ModelsConfig({
|
||||
generationConfig: {
|
||||
model: 'gpt-4o', // From OPENAI_MODEL env var
|
||||
apiKey: 'openai-key-from-env',
|
||||
},
|
||||
});
|
||||
|
||||
// User switches to qwen-oauth via AuthDialog
|
||||
// refreshAuth calls syncAfterAuthRefresh with the current model (gpt-4o)
|
||||
// which doesn't exist in qwen-oauth registry, so it should use default
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.QWEN_OAUTH, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should use default qwen-oauth model (coder-model), not the OPENAI model
|
||||
expect(gc.model).toBe('coder-model');
|
||||
expect(gc.apiKey).toBe('QWEN_OAUTH_DYNAMIC_TOKEN');
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should clear manual credentials when switching from USE_OPENAI to QWEN_OAUTH', () => {
|
||||
// User manually set credentials for OpenAI
|
||||
const modelsConfig = new ModelsConfig({
|
||||
initialAuthType: AuthType.USE_OPENAI,
|
||||
generationConfig: {
|
||||
model: 'gpt-4o',
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
},
|
||||
});
|
||||
|
||||
// Manually set credentials via updateCredentials
|
||||
modelsConfig.updateCredentials({
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
model: 'gpt-4o',
|
||||
});
|
||||
|
||||
// User switches to qwen-oauth
|
||||
// Since authType is not USE_OPENAI, manual credentials should be cleared
|
||||
// and default qwen-oauth model should be applied
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.QWEN_OAUTH, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should use default qwen-oauth model, not preserve manual OpenAI credentials
|
||||
expect(gc.model).toBe('coder-model');
|
||||
expect(gc.apiKey).toBe('QWEN_OAUTH_DYNAMIC_TOKEN');
|
||||
// baseUrl should be set to qwen-oauth default, not preserved from manual OpenAI config
|
||||
expect(gc.baseUrl).toBe('DYNAMIC_QWEN_OAUTH_BASE_URL');
|
||||
expect(gc.apiKeyEnvKey).toBeUndefined();
|
||||
});
|
||||
|
||||
it('should preserve manual credentials when switching to USE_OPENAI', () => {
|
||||
// User manually set credentials
|
||||
const modelsConfig = new ModelsConfig({
|
||||
initialAuthType: AuthType.USE_OPENAI,
|
||||
generationConfig: {
|
||||
model: 'gpt-4o',
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
samplingParams: { temperature: 0.9 },
|
||||
},
|
||||
});
|
||||
|
||||
// Manually set credentials via updateCredentials
|
||||
modelsConfig.updateCredentials({
|
||||
apiKey: 'manual-openai-key',
|
||||
baseUrl: 'https://manual.example.com/v1',
|
||||
model: 'gpt-4o',
|
||||
});
|
||||
|
||||
// User switches to USE_OPENAI (same or different model)
|
||||
// Since authType is USE_OPENAI, manual credentials should be preserved
|
||||
modelsConfig.syncAfterAuthRefresh(AuthType.USE_OPENAI, 'gpt-4o');
|
||||
|
||||
const gc = currentGenerationConfig(modelsConfig);
|
||||
// Should preserve manual credentials
|
||||
expect(gc.model).toBe('gpt-4o');
|
||||
expect(gc.apiKey).toBe('manual-openai-key');
|
||||
expect(gc.baseUrl).toBe('https://manual.example.com/v1');
|
||||
expect(gc.samplingParams?.temperature).toBe(0.9); // Preserved from initial config
|
||||
});
|
||||
|
||||
it('should maintain consistency between currentModelId and _generationConfig.model after initialization', () => {
|
||||
const modelProvidersConfig: ModelProvidersConfig = {
|
||||
openai: [
|
||||
|
||||
@@ -600,7 +600,7 @@ export class ModelsConfig {
|
||||
|
||||
// If credentials were manually set, don't apply modelProvider defaults
|
||||
// Just update the authType and preserve the manually set credentials
|
||||
if (preserveManualCredentials) {
|
||||
if (preserveManualCredentials && authType === AuthType.USE_OPENAI) {
|
||||
this.strictModelProviderSelection = false;
|
||||
this.currentAuthType = authType;
|
||||
if (modelId) {
|
||||
@@ -621,7 +621,17 @@ export class ModelsConfig {
|
||||
this.applyResolvedModelDefaults(resolved);
|
||||
}
|
||||
} else {
|
||||
// If the provided modelId doesn't exist in the registry for the new authType,
|
||||
// use the default model for that authType instead of keeping the old model.
|
||||
// This handles the case where switching from one authType (e.g., OPENAI with
|
||||
// env vars) to another (e.g., qwen-oauth) - we should use the default model
|
||||
// for the new authType, not the old model.
|
||||
this.currentAuthType = authType;
|
||||
const defaultModel =
|
||||
this.modelRegistry.getDefaultModelForAuthType(authType);
|
||||
if (defaultModel) {
|
||||
this.applyResolvedModelDefaults(defaultModel);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@@ -31,6 +31,7 @@ export type ModelGenerationConfig = Pick<
|
||||
| 'disableCacheControl'
|
||||
| 'schemaCompliance'
|
||||
| 'reasoning'
|
||||
| 'customHeaders'
|
||||
>;
|
||||
|
||||
/**
|
||||
|
||||
@@ -559,6 +559,109 @@ export async function getQwenOAuthClient(
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Displays a formatted box with OAuth device authorization URL.
|
||||
* Uses process.stderr.write() to bypass ConsolePatcher and ensure the auth URL
|
||||
* is always visible to users, especially in non-interactive mode.
|
||||
* Using stderr prevents corruption of structured JSON output (which goes to stdout)
|
||||
* and follows the standard Unix convention of user-facing messages to stderr.
|
||||
*/
|
||||
function showFallbackMessage(verificationUriComplete: string): void {
|
||||
const title = 'Qwen OAuth Device Authorization';
|
||||
const url = verificationUriComplete;
|
||||
const minWidth = 70;
|
||||
const maxWidth = 80;
|
||||
const boxWidth = Math.min(Math.max(title.length + 4, minWidth), maxWidth);
|
||||
|
||||
// Calculate the width needed for the box (account for padding)
|
||||
const contentWidth = boxWidth - 4; // Subtract 2 spaces and 2 border chars
|
||||
|
||||
// Helper to wrap text to fit within box width
|
||||
const wrapText = (text: string, width: number): string[] => {
|
||||
// For URLs, break at any character if too long
|
||||
if (text.startsWith('http://') || text.startsWith('https://')) {
|
||||
const lines: string[] = [];
|
||||
for (let i = 0; i < text.length; i += width) {
|
||||
lines.push(text.substring(i, i + width));
|
||||
}
|
||||
return lines;
|
||||
}
|
||||
|
||||
// For regular text, break at word boundaries
|
||||
const words = text.split(' ');
|
||||
const lines: string[] = [];
|
||||
let currentLine = '';
|
||||
|
||||
for (const word of words) {
|
||||
if (currentLine.length + word.length + 1 <= width) {
|
||||
currentLine += (currentLine ? ' ' : '') + word;
|
||||
} else {
|
||||
if (currentLine) {
|
||||
lines.push(currentLine);
|
||||
}
|
||||
currentLine = word.length > width ? word.substring(0, width) : word;
|
||||
}
|
||||
}
|
||||
if (currentLine) {
|
||||
lines.push(currentLine);
|
||||
}
|
||||
return lines;
|
||||
};
|
||||
|
||||
// Build the box borders with title centered in top border
|
||||
// Format: +--- Title ---+
|
||||
const titleWithSpaces = ' ' + title + ' ';
|
||||
const totalDashes = boxWidth - 2 - titleWithSpaces.length; // Subtract corners and title
|
||||
const leftDashes = Math.floor(totalDashes / 2);
|
||||
const rightDashes = totalDashes - leftDashes;
|
||||
const topBorder =
|
||||
'+' +
|
||||
'-'.repeat(leftDashes) +
|
||||
titleWithSpaces +
|
||||
'-'.repeat(rightDashes) +
|
||||
'+';
|
||||
const emptyLine = '|' + ' '.repeat(boxWidth - 2) + '|';
|
||||
const bottomBorder = '+' + '-'.repeat(boxWidth - 2) + '+';
|
||||
|
||||
// Build content lines
|
||||
const instructionLines = wrapText(
|
||||
'Please visit the following URL in your browser to authorize:',
|
||||
contentWidth,
|
||||
);
|
||||
const urlLines = wrapText(url, contentWidth);
|
||||
const waitingLine = 'Waiting for authorization to complete...';
|
||||
|
||||
// Write the box
|
||||
process.stderr.write('\n' + topBorder + '\n');
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write instructions
|
||||
for (const line of instructionLines) {
|
||||
process.stderr.write(
|
||||
'| ' + line + ' '.repeat(contentWidth - line.length) + ' |\n',
|
||||
);
|
||||
}
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write URL
|
||||
for (const line of urlLines) {
|
||||
process.stderr.write(
|
||||
'| ' + line + ' '.repeat(contentWidth - line.length) + ' |\n',
|
||||
);
|
||||
}
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
|
||||
// Write waiting message
|
||||
process.stderr.write(
|
||||
'| ' + waitingLine + ' '.repeat(contentWidth - waitingLine.length) + ' |\n',
|
||||
);
|
||||
|
||||
process.stderr.write(emptyLine + '\n');
|
||||
process.stderr.write(bottomBorder + '\n\n');
|
||||
}
|
||||
|
||||
async function authWithQwenDeviceFlow(
|
||||
client: QwenOAuth2Client,
|
||||
config: Config,
|
||||
@@ -571,6 +674,50 @@ async function authWithQwenDeviceFlow(
|
||||
};
|
||||
qwenOAuth2Events.once(QwenOAuth2Event.AuthCancel, cancelHandler);
|
||||
|
||||
// Helper to check cancellation and return appropriate result
|
||||
const checkCancellation = (): AuthResult | null => {
|
||||
if (!isCancelled) {
|
||||
return null;
|
||||
}
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
};
|
||||
|
||||
// Helper to emit auth progress events
|
||||
const emitAuthProgress = (
|
||||
status: 'polling' | 'success' | 'error' | 'timeout' | 'rate_limit',
|
||||
message: string,
|
||||
): void => {
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, status, message);
|
||||
};
|
||||
|
||||
// Helper to handle browser launch with error handling
|
||||
const launchBrowser = async (url: string): Promise<void> => {
|
||||
try {
|
||||
const childProcess = await open(url);
|
||||
|
||||
// IMPORTANT: Attach an error handler to the returned child process.
|
||||
// Without this, if `open` fails to spawn a process (e.g., `xdg-open` is not found
|
||||
// in a minimal Docker container), it will emit an unhandled 'error' event,
|
||||
// causing the entire Node.js process to crash.
|
||||
if (childProcess) {
|
||||
childProcess.on('error', (err) => {
|
||||
console.debug(
|
||||
'Browser launch failed:',
|
||||
err.message || 'Unknown error',
|
||||
);
|
||||
});
|
||||
}
|
||||
} catch (err) {
|
||||
console.debug(
|
||||
'Failed to open browser:',
|
||||
err instanceof Error ? err.message : 'Unknown error',
|
||||
);
|
||||
}
|
||||
};
|
||||
|
||||
try {
|
||||
// Generate PKCE code verifier and challenge
|
||||
const { code_verifier, code_challenge } = generatePKCEPair();
|
||||
@@ -593,56 +740,18 @@ async function authWithQwenDeviceFlow(
|
||||
// Emit device authorization event for UI integration immediately
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthUri, deviceAuth);
|
||||
|
||||
const showFallbackMessage = () => {
|
||||
console.log('\n=== Qwen OAuth Device Authorization ===');
|
||||
console.log(
|
||||
'Please visit the following URL in your browser to authorize:',
|
||||
);
|
||||
console.log(`\n${deviceAuth.verification_uri_complete}\n`);
|
||||
console.log('Waiting for authorization to complete...\n');
|
||||
};
|
||||
|
||||
// Always show the fallback message in non-interactive environments to ensure
|
||||
// users can see the authorization URL even if browser launching is attempted.
|
||||
// This is critical for headless/remote environments where browser launching
|
||||
// may silently fail without throwing an error.
|
||||
if (config.isBrowserLaunchSuppressed()) {
|
||||
// Browser launch is suppressed, show fallback message
|
||||
showFallbackMessage();
|
||||
} else {
|
||||
// Try to open the URL in browser, but always show the URL as fallback
|
||||
// to handle cases where browser launch silently fails (e.g., headless servers)
|
||||
showFallbackMessage();
|
||||
try {
|
||||
const childProcess = await open(deviceAuth.verification_uri_complete);
|
||||
showFallbackMessage(deviceAuth.verification_uri_complete);
|
||||
|
||||
// IMPORTANT: Attach an error handler to the returned child process.
|
||||
// Without this, if `open` fails to spawn a process (e.g., `xdg-open` is not found
|
||||
// in a minimal Docker container), it will emit an unhandled 'error' event,
|
||||
// causing the entire Node.js process to crash.
|
||||
if (childProcess) {
|
||||
childProcess.on('error', (err) => {
|
||||
console.debug(
|
||||
'Browser launch failed:',
|
||||
err.message || 'Unknown error',
|
||||
);
|
||||
});
|
||||
}
|
||||
} catch (err) {
|
||||
console.debug(
|
||||
'Failed to open browser:',
|
||||
err instanceof Error ? err.message : 'Unknown error',
|
||||
);
|
||||
}
|
||||
// Try to open browser if not suppressed
|
||||
if (!config.isBrowserLaunchSuppressed()) {
|
||||
await launchBrowser(deviceAuth.verification_uri_complete);
|
||||
}
|
||||
|
||||
// Emit auth progress event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'polling',
|
||||
'Waiting for authorization...',
|
||||
);
|
||||
|
||||
emitAuthProgress('polling', 'Waiting for authorization...');
|
||||
console.debug('Waiting for authorization...\n');
|
||||
|
||||
// Poll for the token
|
||||
@@ -653,11 +762,9 @@ async function authWithQwenDeviceFlow(
|
||||
|
||||
for (let attempt = 0; attempt < maxAttempts; attempt++) {
|
||||
// Check if authentication was cancelled
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
}
|
||||
|
||||
try {
|
||||
@@ -700,9 +807,7 @@ async function authWithQwenDeviceFlow(
|
||||
// minimal stub; cache invalidation is best-effort and should not break auth.
|
||||
}
|
||||
|
||||
// Emit auth progress success event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
emitAuthProgress(
|
||||
'success',
|
||||
'Authentication successful! Access token obtained.',
|
||||
);
|
||||
@@ -725,9 +830,7 @@ async function authWithQwenDeviceFlow(
|
||||
pollInterval = 2000; // Reset to default interval
|
||||
}
|
||||
|
||||
// Emit polling progress event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
emitAuthProgress(
|
||||
'polling',
|
||||
`Polling... (attempt ${attempt + 1}/${maxAttempts})`,
|
||||
);
|
||||
@@ -757,15 +860,9 @@ async function authWithQwenDeviceFlow(
|
||||
});
|
||||
|
||||
// Check for cancellation after waiting
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
console.debug('\n' + message);
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'error',
|
||||
message,
|
||||
);
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
}
|
||||
|
||||
continue;
|
||||
@@ -793,15 +890,17 @@ async function authWithQwenDeviceFlow(
|
||||
message: string,
|
||||
eventType: 'error' | 'rate_limit' = 'error',
|
||||
): AuthResult => {
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
eventType,
|
||||
message,
|
||||
);
|
||||
emitAuthProgress(eventType, message);
|
||||
console.error('\n' + message);
|
||||
return { success: false, reason, message };
|
||||
};
|
||||
|
||||
// Check for cancellation first
|
||||
const cancellationResult = checkCancellation();
|
||||
if (cancellationResult) {
|
||||
return cancellationResult;
|
||||
}
|
||||
|
||||
// Handle credential caching failures - stop polling immediately
|
||||
if (errorMessage.includes('Failed to cache credentials')) {
|
||||
return handleError('error', errorMessage);
|
||||
@@ -825,26 +924,14 @@ async function authWithQwenDeviceFlow(
|
||||
}
|
||||
|
||||
const message = `Error polling for token: ${errorMessage}`;
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
|
||||
if (isCancelled) {
|
||||
const message = 'Authentication cancelled by user.';
|
||||
return { success: false, reason: 'cancelled', message };
|
||||
}
|
||||
emitAuthProgress('error', message);
|
||||
|
||||
await new Promise((resolve) => setTimeout(resolve, pollInterval));
|
||||
}
|
||||
}
|
||||
|
||||
const timeoutMessage = 'Authorization timeout, please restart the process.';
|
||||
|
||||
// Emit timeout error event
|
||||
qwenOAuth2Events.emit(
|
||||
QwenOAuth2Event.AuthProgress,
|
||||
'timeout',
|
||||
timeoutMessage,
|
||||
);
|
||||
|
||||
emitAuthProgress('timeout', timeoutMessage);
|
||||
console.error('\n' + timeoutMessage);
|
||||
return { success: false, reason: 'timeout', message: timeoutMessage };
|
||||
} catch (error: unknown) {
|
||||
@@ -853,7 +940,7 @@ async function authWithQwenDeviceFlow(
|
||||
});
|
||||
const message = `Device authorization flow failed: ${fullErrorMessage}`;
|
||||
|
||||
qwenOAuth2Events.emit(QwenOAuth2Event.AuthProgress, 'error', message);
|
||||
emitAuthProgress('error', message);
|
||||
console.error(message);
|
||||
return { success: false, reason: 'error', message };
|
||||
} finally {
|
||||
|
||||
@@ -15,13 +15,11 @@ import { uiTelemetryService } from '../telemetry/uiTelemetry.js';
|
||||
import { tokenLimit } from '../core/tokenLimits.js';
|
||||
import type { GeminiChat } from '../core/geminiChat.js';
|
||||
import type { Config } from '../config/config.js';
|
||||
import { getInitialChatHistory } from '../utils/environmentContext.js';
|
||||
import type { ContentGenerator } from '../core/contentGenerator.js';
|
||||
|
||||
vi.mock('../telemetry/uiTelemetry.js');
|
||||
vi.mock('../core/tokenLimits.js');
|
||||
vi.mock('../telemetry/loggers.js');
|
||||
vi.mock('../utils/environmentContext.js');
|
||||
|
||||
describe('findCompressSplitPoint', () => {
|
||||
it('should throw an error for non-positive numbers', () => {
|
||||
@@ -122,9 +120,6 @@ describe('ChatCompressionService', () => {
|
||||
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(500);
|
||||
vi.mocked(getInitialChatHistory).mockImplementation(
|
||||
async (_config, extraHistory) => extraHistory || [],
|
||||
);
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
@@ -241,6 +236,7 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(mockChat.getHistory).mockReturnValue(history);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(800);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
// newTokenCount = 800 - (1600 - 1000) + 50 = 800 - 600 + 50 = 250 <= 800 (success)
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -249,6 +245,11 @@ describe('ChatCompressionService', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1600,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1650,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -264,6 +265,7 @@ describe('ChatCompressionService', () => {
|
||||
);
|
||||
|
||||
expect(result.info.compressionStatus).toBe(CompressionStatus.COMPRESSED);
|
||||
expect(result.info.newTokenCount).toBe(250); // 800 - (1600 - 1000) + 50
|
||||
expect(result.newHistory).not.toBeNull();
|
||||
expect(result.newHistory![0].parts![0].text).toBe('Summary');
|
||||
expect(mockGenerateContent).toHaveBeenCalled();
|
||||
@@ -280,6 +282,7 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(100);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
// newTokenCount = 100 - (1100 - 1000) + 50 = 100 - 100 + 50 = 50 <= 100 (success)
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
@@ -288,6 +291,11 @@ describe('ChatCompressionService', () => {
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1100,
|
||||
candidatesTokenCount: 50,
|
||||
totalTokenCount: 1150,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -315,15 +323,19 @@ describe('ChatCompressionService', () => {
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(10);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
const longSummary = 'a'.repeat(1000); // Long summary to inflate token count
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
content: {
|
||||
parts: [{ text: longSummary }],
|
||||
parts: [{ text: 'Summary' }],
|
||||
},
|
||||
},
|
||||
],
|
||||
usageMetadata: {
|
||||
promptTokenCount: 1,
|
||||
candidatesTokenCount: 20,
|
||||
totalTokenCount: 21,
|
||||
},
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
@@ -344,6 +356,48 @@ describe('ChatCompressionService', () => {
|
||||
expect(result.newHistory).toBeNull();
|
||||
});
|
||||
|
||||
it('should return FAILED if usage metadata is missing', async () => {
|
||||
const history: Content[] = [
|
||||
{ role: 'user', parts: [{ text: 'msg1' }] },
|
||||
{ role: 'model', parts: [{ text: 'msg2' }] },
|
||||
{ role: 'user', parts: [{ text: 'msg3' }] },
|
||||
{ role: 'model', parts: [{ text: 'msg4' }] },
|
||||
];
|
||||
vi.mocked(mockChat.getHistory).mockReturnValue(history);
|
||||
vi.mocked(uiTelemetryService.getLastPromptTokenCount).mockReturnValue(800);
|
||||
vi.mocked(tokenLimit).mockReturnValue(1000);
|
||||
|
||||
const mockGenerateContent = vi.fn().mockResolvedValue({
|
||||
candidates: [
|
||||
{
|
||||
content: {
|
||||
parts: [{ text: 'Summary' }],
|
||||
},
|
||||
},
|
||||
],
|
||||
// No usageMetadata -> keep original token count
|
||||
} as unknown as GenerateContentResponse);
|
||||
vi.mocked(mockConfig.getContentGenerator).mockReturnValue({
|
||||
generateContent: mockGenerateContent,
|
||||
} as unknown as ContentGenerator);
|
||||
|
||||
const result = await service.compress(
|
||||
mockChat,
|
||||
mockPromptId,
|
||||
false,
|
||||
mockModel,
|
||||
mockConfig,
|
||||
false,
|
||||
);
|
||||
|
||||
expect(result.info.compressionStatus).toBe(
|
||||
CompressionStatus.COMPRESSION_FAILED_TOKEN_COUNT_ERROR,
|
||||
);
|
||||
expect(result.info.originalTokenCount).toBe(800);
|
||||
expect(result.info.newTokenCount).toBe(800);
|
||||
expect(result.newHistory).toBeNull();
|
||||
});
|
||||
|
||||
it('should return FAILED if summary is empty string', async () => {
|
||||
const history: Content[] = [
|
||||
{ role: 'user', parts: [{ text: 'msg1' }] },
|
||||
|
||||
@@ -14,7 +14,6 @@ import { getCompressionPrompt } from '../core/prompts.js';
|
||||
import { getResponseText } from '../utils/partUtils.js';
|
||||
import { logChatCompression } from '../telemetry/loggers.js';
|
||||
import { makeChatCompressionEvent } from '../telemetry/types.js';
|
||||
import { getInitialChatHistory } from '../utils/environmentContext.js';
|
||||
|
||||
/**
|
||||
* Threshold for compression token count as a fraction of the model's token limit.
|
||||
@@ -163,9 +162,25 @@ export class ChatCompressionService {
|
||||
);
|
||||
const summary = getResponseText(summaryResponse) ?? '';
|
||||
const isSummaryEmpty = !summary || summary.trim().length === 0;
|
||||
const compressionUsageMetadata = summaryResponse.usageMetadata;
|
||||
const compressionInputTokenCount =
|
||||
compressionUsageMetadata?.promptTokenCount;
|
||||
let compressionOutputTokenCount =
|
||||
compressionUsageMetadata?.candidatesTokenCount;
|
||||
if (
|
||||
compressionOutputTokenCount === undefined &&
|
||||
typeof compressionUsageMetadata?.totalTokenCount === 'number' &&
|
||||
typeof compressionInputTokenCount === 'number'
|
||||
) {
|
||||
compressionOutputTokenCount = Math.max(
|
||||
0,
|
||||
compressionUsageMetadata.totalTokenCount - compressionInputTokenCount,
|
||||
);
|
||||
}
|
||||
|
||||
let newTokenCount = originalTokenCount;
|
||||
let extraHistory: Content[] = [];
|
||||
let canCalculateNewTokenCount = false;
|
||||
|
||||
if (!isSummaryEmpty) {
|
||||
extraHistory = [
|
||||
@@ -180,16 +195,26 @@ export class ChatCompressionService {
|
||||
...historyToKeep,
|
||||
];
|
||||
|
||||
// Use a shared utility to construct the initial history for an accurate token count.
|
||||
const fullNewHistory = await getInitialChatHistory(config, extraHistory);
|
||||
|
||||
// Estimate token count 1 token ≈ 4 characters
|
||||
newTokenCount = Math.floor(
|
||||
fullNewHistory.reduce(
|
||||
(total, content) => total + JSON.stringify(content).length,
|
||||
// Best-effort token math using *only* model-reported token counts.
|
||||
//
|
||||
// Note: compressionInputTokenCount includes the compression prompt and
|
||||
// the extra "reason in your scratchpad" instruction(approx. 1000 tokens), and
|
||||
// compressionOutputTokenCount may include non-persisted tokens (thoughts).
|
||||
// We accept these inaccuracies to avoid local token estimation.
|
||||
if (
|
||||
typeof compressionInputTokenCount === 'number' &&
|
||||
compressionInputTokenCount > 0 &&
|
||||
typeof compressionOutputTokenCount === 'number' &&
|
||||
compressionOutputTokenCount > 0
|
||||
) {
|
||||
canCalculateNewTokenCount = true;
|
||||
newTokenCount = Math.max(
|
||||
0,
|
||||
) / 4,
|
||||
);
|
||||
originalTokenCount -
|
||||
(compressionInputTokenCount - 1000) +
|
||||
compressionOutputTokenCount,
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
logChatCompression(
|
||||
@@ -197,6 +222,8 @@ export class ChatCompressionService {
|
||||
makeChatCompressionEvent({
|
||||
tokens_before: originalTokenCount,
|
||||
tokens_after: newTokenCount,
|
||||
compression_input_token_count: compressionInputTokenCount,
|
||||
compression_output_token_count: compressionOutputTokenCount,
|
||||
}),
|
||||
);
|
||||
|
||||
@@ -209,6 +236,16 @@ export class ChatCompressionService {
|
||||
compressionStatus: CompressionStatus.COMPRESSION_FAILED_EMPTY_SUMMARY,
|
||||
},
|
||||
};
|
||||
} else if (!canCalculateNewTokenCount) {
|
||||
return {
|
||||
newHistory: null,
|
||||
info: {
|
||||
originalTokenCount,
|
||||
newTokenCount: originalTokenCount,
|
||||
compressionStatus:
|
||||
CompressionStatus.COMPRESSION_FAILED_TOKEN_COUNT_ERROR,
|
||||
},
|
||||
};
|
||||
} else if (newTokenCount > originalTokenCount) {
|
||||
return {
|
||||
newHistory: null,
|
||||
|
||||
@@ -439,17 +439,27 @@ export interface ChatCompressionEvent extends BaseTelemetryEvent {
|
||||
'event.timestamp': string;
|
||||
tokens_before: number;
|
||||
tokens_after: number;
|
||||
compression_input_token_count?: number;
|
||||
compression_output_token_count?: number;
|
||||
}
|
||||
|
||||
export function makeChatCompressionEvent({
|
||||
tokens_before,
|
||||
tokens_after,
|
||||
compression_input_token_count,
|
||||
compression_output_token_count,
|
||||
}: Omit<ChatCompressionEvent, CommonFields>): ChatCompressionEvent {
|
||||
return {
|
||||
'event.name': 'chat_compression',
|
||||
'event.timestamp': new Date().toISOString(),
|
||||
tokens_before,
|
||||
tokens_after,
|
||||
...(compression_input_token_count !== undefined
|
||||
? { compression_input_token_count }
|
||||
: {}),
|
||||
...(compression_output_token_count !== undefined
|
||||
? { compression_output_token_count }
|
||||
: {}),
|
||||
};
|
||||
}
|
||||
|
||||
|
||||
@@ -4,37 +4,8 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
export { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
import { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
export { RequestTokenizer as RequestTokenEstimator } from './requestTokenizer.js';
|
||||
export { TextTokenizer } from './textTokenizer.js';
|
||||
export { ImageTokenizer } from './imageTokenizer.js';
|
||||
|
||||
export type {
|
||||
RequestTokenizer,
|
||||
TokenizerConfig,
|
||||
TokenCalculationResult,
|
||||
ImageMetadata,
|
||||
} from './types.js';
|
||||
|
||||
// Singleton instance for convenient usage
|
||||
let defaultTokenizer: DefaultRequestTokenizer | null = null;
|
||||
|
||||
/**
|
||||
* Get the default request tokenizer instance
|
||||
*/
|
||||
export function getDefaultTokenizer(): DefaultRequestTokenizer {
|
||||
if (!defaultTokenizer) {
|
||||
defaultTokenizer = new DefaultRequestTokenizer();
|
||||
}
|
||||
return defaultTokenizer;
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of the default tokenizer instance
|
||||
*/
|
||||
export async function disposeDefaultTokenizer(): Promise<void> {
|
||||
if (defaultTokenizer) {
|
||||
await defaultTokenizer.dispose();
|
||||
defaultTokenizer = null;
|
||||
}
|
||||
}
|
||||
export type { TokenCalculationResult, ImageMetadata } from './types.js';
|
||||
|
||||
@@ -4,19 +4,15 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import { describe, it, expect, beforeEach, afterEach } from 'vitest';
|
||||
import { DefaultRequestTokenizer } from './requestTokenizer.js';
|
||||
import { describe, it, expect, beforeEach } from 'vitest';
|
||||
import { RequestTokenizer } from './requestTokenizer.js';
|
||||
import type { CountTokensParameters } from '@google/genai';
|
||||
|
||||
describe('DefaultRequestTokenizer', () => {
|
||||
let tokenizer: DefaultRequestTokenizer;
|
||||
describe('RequestTokenEstimator', () => {
|
||||
let tokenizer: RequestTokenizer;
|
||||
|
||||
beforeEach(() => {
|
||||
tokenizer = new DefaultRequestTokenizer();
|
||||
});
|
||||
|
||||
afterEach(async () => {
|
||||
await tokenizer.dispose();
|
||||
tokenizer = new RequestTokenizer();
|
||||
});
|
||||
|
||||
describe('text token calculation', () => {
|
||||
@@ -221,25 +217,7 @@ describe('DefaultRequestTokenizer', () => {
|
||||
});
|
||||
});
|
||||
|
||||
describe('configuration', () => {
|
||||
it('should use custom text encoding', async () => {
|
||||
const request: CountTokensParameters = {
|
||||
model: 'test-model',
|
||||
contents: [
|
||||
{
|
||||
role: 'user',
|
||||
parts: [{ text: 'Test text for encoding' }],
|
||||
},
|
||||
],
|
||||
};
|
||||
|
||||
const result = await tokenizer.calculateTokens(request, {
|
||||
textEncoding: 'cl100k_base',
|
||||
});
|
||||
|
||||
expect(result.totalTokens).toBeGreaterThan(0);
|
||||
});
|
||||
|
||||
describe('images', () => {
|
||||
it('should process multiple images serially', async () => {
|
||||
const pngBase64 =
|
||||
'iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mNkYPhfDwAChAI9jU77yQAAAABJRU5ErkJggg==';
|
||||
|
||||
@@ -10,18 +10,14 @@ import type {
|
||||
Part,
|
||||
PartUnion,
|
||||
} from '@google/genai';
|
||||
import type {
|
||||
RequestTokenizer,
|
||||
TokenizerConfig,
|
||||
TokenCalculationResult,
|
||||
} from './types.js';
|
||||
import type { TokenCalculationResult } from './types.js';
|
||||
import { TextTokenizer } from './textTokenizer.js';
|
||||
import { ImageTokenizer } from './imageTokenizer.js';
|
||||
|
||||
/**
|
||||
* Simple request tokenizer that handles text and image content serially
|
||||
* Simple request token estimator that handles text and image content serially
|
||||
*/
|
||||
export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
export class RequestTokenizer {
|
||||
private textTokenizer: TextTokenizer;
|
||||
private imageTokenizer: ImageTokenizer;
|
||||
|
||||
@@ -35,15 +31,9 @@ export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
*/
|
||||
async calculateTokens(
|
||||
request: CountTokensParameters,
|
||||
config: TokenizerConfig = {},
|
||||
): Promise<TokenCalculationResult> {
|
||||
const startTime = performance.now();
|
||||
|
||||
// Apply configuration
|
||||
if (config.textEncoding) {
|
||||
this.textTokenizer = new TextTokenizer(config.textEncoding);
|
||||
}
|
||||
|
||||
try {
|
||||
// Process request content and group by type
|
||||
const { textContents, imageContents, audioContents, otherContents } =
|
||||
@@ -112,9 +102,8 @@ export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
if (textContents.length === 0) return 0;
|
||||
|
||||
try {
|
||||
const tokenCounts =
|
||||
await this.textTokenizer.calculateTokensBatch(textContents);
|
||||
return tokenCounts.reduce((sum, count) => sum + count, 0);
|
||||
// Avoid per-part rounding inflation by estimating once on the combined text.
|
||||
return await this.textTokenizer.calculateTokens(textContents.join(''));
|
||||
} catch (error) {
|
||||
console.warn('Error calculating text tokens:', error);
|
||||
// Fallback: character-based estimation
|
||||
@@ -177,10 +166,8 @@ export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
if (otherContents.length === 0) return 0;
|
||||
|
||||
try {
|
||||
// Treat other content as text for token calculation
|
||||
const tokenCounts =
|
||||
await this.textTokenizer.calculateTokensBatch(otherContents);
|
||||
return tokenCounts.reduce((sum, count) => sum + count, 0);
|
||||
// Treat other content as text, and avoid per-item rounding inflation.
|
||||
return await this.textTokenizer.calculateTokens(otherContents.join(''));
|
||||
} catch (error) {
|
||||
console.warn('Error calculating other content tokens:', error);
|
||||
// Fallback: character-based estimation
|
||||
@@ -264,7 +251,18 @@ export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
otherContents,
|
||||
);
|
||||
}
|
||||
return;
|
||||
}
|
||||
|
||||
// Some request shapes (e.g. CountTokensParameters) allow passing parts directly
|
||||
// instead of wrapping them in a { parts: [...] } Content object.
|
||||
this.processPart(
|
||||
content as Part | string,
|
||||
textContents,
|
||||
imageContents,
|
||||
audioContents,
|
||||
otherContents,
|
||||
);
|
||||
}
|
||||
|
||||
/**
|
||||
@@ -326,16 +324,4 @@ export class DefaultRequestTokenizer implements RequestTokenizer {
|
||||
console.warn('Failed to serialize unknown part type:', error);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of resources
|
||||
*/
|
||||
async dispose(): Promise<void> {
|
||||
try {
|
||||
// Dispose of tokenizers
|
||||
this.textTokenizer.dispose();
|
||||
} catch (error) {
|
||||
console.warn('Error disposing request tokenizer:', error);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,36 +4,14 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import { describe, it, expect, vi, beforeEach, afterEach } from 'vitest';
|
||||
import { describe, it, expect, beforeEach } from 'vitest';
|
||||
import { TextTokenizer } from './textTokenizer.js';
|
||||
|
||||
// Mock tiktoken at the top level with hoisted functions
|
||||
const mockEncode = vi.hoisted(() => vi.fn());
|
||||
const mockFree = vi.hoisted(() => vi.fn());
|
||||
const mockGetEncoding = vi.hoisted(() => vi.fn());
|
||||
|
||||
vi.mock('tiktoken', () => ({
|
||||
get_encoding: mockGetEncoding,
|
||||
}));
|
||||
|
||||
describe('TextTokenizer', () => {
|
||||
let tokenizer: TextTokenizer;
|
||||
let consoleWarnSpy: ReturnType<typeof vi.spyOn>;
|
||||
|
||||
beforeEach(() => {
|
||||
vi.resetAllMocks();
|
||||
consoleWarnSpy = vi.spyOn(console, 'warn').mockImplementation(() => {});
|
||||
|
||||
// Default mock implementation
|
||||
mockGetEncoding.mockReturnValue({
|
||||
encode: mockEncode,
|
||||
free: mockFree,
|
||||
});
|
||||
});
|
||||
|
||||
afterEach(() => {
|
||||
vi.restoreAllMocks();
|
||||
tokenizer?.dispose();
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
describe('constructor', () => {
|
||||
@@ -42,17 +20,14 @@ describe('TextTokenizer', () => {
|
||||
expect(tokenizer).toBeInstanceOf(TextTokenizer);
|
||||
});
|
||||
|
||||
it('should create tokenizer with custom encoding', () => {
|
||||
tokenizer = new TextTokenizer('gpt2');
|
||||
it('should create tokenizer with custom encoding (for backward compatibility)', () => {
|
||||
tokenizer = new TextTokenizer();
|
||||
expect(tokenizer).toBeInstanceOf(TextTokenizer);
|
||||
// Note: encoding name is accepted but not used
|
||||
});
|
||||
});
|
||||
|
||||
describe('calculateTokens', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should return 0 for empty text', async () => {
|
||||
const result = await tokenizer.calculateTokens('');
|
||||
expect(result).toBe(0);
|
||||
@@ -69,99 +44,77 @@ describe('TextTokenizer', () => {
|
||||
expect(result2).toBe(0);
|
||||
});
|
||||
|
||||
it('should calculate tokens using tiktoken when available', async () => {
|
||||
const testText = 'Hello, world!';
|
||||
const mockTokens = [1, 2, 3, 4, 5]; // 5 tokens
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
it('should calculate tokens using character-based estimation for ASCII text', async () => {
|
||||
const testText = 'Hello, world!'; // 13 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
// 13 / 4 = 3.25 -> ceil = 4
|
||||
expect(result).toBe(4);
|
||||
});
|
||||
|
||||
expect(mockGetEncoding).toHaveBeenCalledWith('cl100k_base');
|
||||
expect(mockEncode).toHaveBeenCalledWith(testText);
|
||||
it('should calculate tokens for code (ASCII)', async () => {
|
||||
const code = 'function test() { return 42; }'; // 30 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(code);
|
||||
// 30 / 4 = 7.5 -> ceil = 8
|
||||
expect(result).toBe(8);
|
||||
});
|
||||
|
||||
it('should calculate tokens for non-ASCII text (CJK)', async () => {
|
||||
const unicodeText = '你好世界'; // 4 non-ASCII chars
|
||||
const result = await tokenizer.calculateTokens(unicodeText);
|
||||
// 4 * 1.1 = 4.4 -> ceil = 5
|
||||
expect(result).toBe(5);
|
||||
});
|
||||
|
||||
it('should use fallback calculation when tiktoken fails to load', async () => {
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load tiktoken');
|
||||
});
|
||||
|
||||
const testText = 'Hello, world!'; // 13 characters
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Failed to load tiktoken with encoding cl100k_base:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(13 / 4) = 4
|
||||
it('should calculate tokens for mixed ASCII and non-ASCII text', async () => {
|
||||
const mixedText = 'Hello 世界'; // 6 ASCII + 2 non-ASCII
|
||||
const result = await tokenizer.calculateTokens(mixedText);
|
||||
// (6 / 4) + (2 * 1.1) = 1.5 + 2.2 = 3.7 -> ceil = 4
|
||||
expect(result).toBe(4);
|
||||
});
|
||||
|
||||
it('should use fallback calculation when encoding fails', async () => {
|
||||
mockEncode.mockImplementation(() => {
|
||||
throw new Error('Encoding failed');
|
||||
});
|
||||
|
||||
const testText = 'Hello, world!'; // 13 characters
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error encoding text with tiktoken:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(13 / 4) = 4
|
||||
expect(result).toBe(4);
|
||||
it('should calculate tokens for emoji', async () => {
|
||||
const emojiText = '🌍'; // 2 UTF-16 code units (non-ASCII)
|
||||
const result = await tokenizer.calculateTokens(emojiText);
|
||||
// 2 * 1.1 = 2.2 -> ceil = 3
|
||||
expect(result).toBe(3);
|
||||
});
|
||||
|
||||
it('should handle very long text', async () => {
|
||||
const longText = 'a'.repeat(10000);
|
||||
const mockTokens = new Array(2500); // 2500 tokens
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const longText = 'a'.repeat(10000); // 10000 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(longText);
|
||||
|
||||
// 10000 / 4 = 2500 -> ceil = 2500
|
||||
expect(result).toBe(2500);
|
||||
});
|
||||
|
||||
it('should handle unicode characters', async () => {
|
||||
const unicodeText = '你好世界 🌍';
|
||||
const mockTokens = [1, 2, 3, 4, 5, 6];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(unicodeText);
|
||||
|
||||
expect(result).toBe(6);
|
||||
it('should handle text with only whitespace', async () => {
|
||||
const whitespaceText = ' \n\t '; // 7 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(whitespaceText);
|
||||
// 7 / 4 = 1.75 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
});
|
||||
|
||||
it('should use custom encoding when specified', async () => {
|
||||
tokenizer = new TextTokenizer('gpt2');
|
||||
const testText = 'Hello, world!';
|
||||
const mockTokens = [1, 2, 3];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
it('should handle special characters and symbols', async () => {
|
||||
const specialText = '!@#$%^&*()_+-=[]{}|;:,.<>?'; // 26 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(specialText);
|
||||
// 26 / 4 = 6.5 -> ceil = 7
|
||||
expect(result).toBe(7);
|
||||
});
|
||||
|
||||
const result = await tokenizer.calculateTokens(testText);
|
||||
|
||||
expect(mockGetEncoding).toHaveBeenCalledWith('gpt2');
|
||||
expect(result).toBe(3);
|
||||
it('should handle very short text', async () => {
|
||||
const result = await tokenizer.calculateTokens('a');
|
||||
// 1 / 4 = 0.25 -> ceil = 1
|
||||
expect(result).toBe(1);
|
||||
});
|
||||
});
|
||||
|
||||
describe('calculateTokensBatch', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should process multiple texts and return token counts', async () => {
|
||||
const texts = ['Hello', 'world', 'test'];
|
||||
mockEncode
|
||||
.mockReturnValueOnce([1, 2]) // 2 tokens for 'Hello'
|
||||
.mockReturnValueOnce([3, 4, 5]) // 3 tokens for 'world'
|
||||
.mockReturnValueOnce([6]); // 1 token for 'test'
|
||||
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
|
||||
expect(result).toEqual([2, 3, 1]);
|
||||
expect(mockEncode).toHaveBeenCalledTimes(3);
|
||||
// 'Hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// 'world' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// 'test' = 4 / 4 = 1 -> ceil = 1
|
||||
expect(result).toEqual([2, 2, 1]);
|
||||
});
|
||||
|
||||
it('should handle empty array', async () => {
|
||||
@@ -171,177 +124,156 @@ describe('TextTokenizer', () => {
|
||||
|
||||
it('should handle array with empty strings', async () => {
|
||||
const texts = ['', 'hello', ''];
|
||||
mockEncode.mockReturnValue([1, 2, 3]); // Only called for 'hello'
|
||||
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
|
||||
expect(result).toEqual([0, 3, 0]);
|
||||
expect(mockEncode).toHaveBeenCalledTimes(1);
|
||||
expect(mockEncode).toHaveBeenCalledWith('hello');
|
||||
// '' = 0
|
||||
// 'hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// '' = 0
|
||||
expect(result).toEqual([0, 2, 0]);
|
||||
});
|
||||
|
||||
it('should use fallback calculation when tiktoken fails to load', async () => {
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load tiktoken');
|
||||
});
|
||||
|
||||
const texts = ['Hello', 'world']; // 5 and 5 characters
|
||||
it('should handle mixed ASCII and non-ASCII texts', async () => {
|
||||
const texts = ['Hello', '世界', 'Hello 世界'];
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Failed to load tiktoken with encoding cl100k_base:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(5/4) = 2 for both
|
||||
expect(result).toEqual([2, 2]);
|
||||
});
|
||||
|
||||
it('should use fallback calculation when encoding fails during batch processing', async () => {
|
||||
mockEncode.mockImplementation(() => {
|
||||
throw new Error('Encoding failed');
|
||||
});
|
||||
|
||||
const texts = ['Hello', 'world']; // 5 and 5 characters
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error encoding texts with tiktoken:',
|
||||
expect.any(Error),
|
||||
);
|
||||
// Fallback: Math.ceil(5/4) = 2 for both
|
||||
expect(result).toEqual([2, 2]);
|
||||
// 'Hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// '世界' = 2 * 1.1 = 2.2 -> ceil = 3
|
||||
// 'Hello 世界' = (6/4) + (2*1.1) = 1.5 + 2.2 = 3.7 -> ceil = 4
|
||||
expect(result).toEqual([2, 3, 4]);
|
||||
});
|
||||
|
||||
it('should handle null and undefined values in batch', async () => {
|
||||
const texts = [null, 'hello', undefined, 'world'] as unknown as string[];
|
||||
mockEncode
|
||||
.mockReturnValueOnce([1, 2, 3]) // 3 tokens for 'hello'
|
||||
.mockReturnValueOnce([4, 5]); // 2 tokens for 'world'
|
||||
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
// null = 0
|
||||
// 'hello' = 5 / 4 = 1.25 -> ceil = 2
|
||||
// undefined = 0
|
||||
// 'world' = 5 / 4 = 1.25 -> ceil = 2
|
||||
expect(result).toEqual([0, 2, 0, 2]);
|
||||
});
|
||||
|
||||
expect(result).toEqual([0, 3, 0, 2]);
|
||||
it('should process large batches efficiently', async () => {
|
||||
const texts = Array.from({ length: 1000 }, (_, i) => `text${i}`);
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
expect(result).toHaveLength(1000);
|
||||
// Verify results are reasonable
|
||||
result.forEach((count) => {
|
||||
expect(count).toBeGreaterThan(0);
|
||||
expect(count).toBeLessThan(10); // 'textNNN' should be less than 10 tokens
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
describe('dispose', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
describe('backward compatibility', () => {
|
||||
it('should accept encoding parameter in constructor', () => {
|
||||
const tokenizer1 = new TextTokenizer();
|
||||
const tokenizer2 = new TextTokenizer();
|
||||
const tokenizer3 = new TextTokenizer();
|
||||
|
||||
expect(tokenizer1).toBeInstanceOf(TextTokenizer);
|
||||
expect(tokenizer2).toBeInstanceOf(TextTokenizer);
|
||||
expect(tokenizer3).toBeInstanceOf(TextTokenizer);
|
||||
});
|
||||
|
||||
it('should free tiktoken encoding when disposing', async () => {
|
||||
// Initialize the encoding by calling calculateTokens
|
||||
await tokenizer.calculateTokens('test');
|
||||
it('should produce same results regardless of encoding parameter', async () => {
|
||||
const text = 'Hello, world!';
|
||||
const tokenizer1 = new TextTokenizer();
|
||||
const tokenizer2 = new TextTokenizer();
|
||||
const tokenizer3 = new TextTokenizer();
|
||||
|
||||
tokenizer.dispose();
|
||||
const result1 = await tokenizer1.calculateTokens(text);
|
||||
const result2 = await tokenizer2.calculateTokens(text);
|
||||
const result3 = await tokenizer3.calculateTokens(text);
|
||||
|
||||
expect(mockFree).toHaveBeenCalled();
|
||||
// All should use character-based estimation, ignoring encoding parameter
|
||||
expect(result1).toBe(result2);
|
||||
expect(result2).toBe(result3);
|
||||
expect(result1).toBe(4); // 13 / 4 = 3.25 -> ceil = 4
|
||||
});
|
||||
|
||||
it('should handle disposal when encoding is not initialized', () => {
|
||||
expect(() => tokenizer.dispose()).not.toThrow();
|
||||
expect(mockFree).not.toHaveBeenCalled();
|
||||
it('should maintain async interface for calculateTokens', async () => {
|
||||
const result = tokenizer.calculateTokens('test');
|
||||
expect(result).toBeInstanceOf(Promise);
|
||||
await expect(result).resolves.toBe(1);
|
||||
});
|
||||
|
||||
it('should handle disposal when encoding is null', async () => {
|
||||
// Force encoding to be null by making tiktoken fail
|
||||
mockGetEncoding.mockImplementation(() => {
|
||||
throw new Error('Failed to load');
|
||||
});
|
||||
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
expect(() => tokenizer.dispose()).not.toThrow();
|
||||
expect(mockFree).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should handle errors during disposal gracefully', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
mockFree.mockImplementation(() => {
|
||||
throw new Error('Free failed');
|
||||
});
|
||||
|
||||
tokenizer.dispose();
|
||||
|
||||
expect(consoleWarnSpy).toHaveBeenCalledWith(
|
||||
'Error freeing tiktoken encoding:',
|
||||
expect.any(Error),
|
||||
);
|
||||
});
|
||||
|
||||
it('should allow multiple calls to dispose', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
|
||||
tokenizer.dispose();
|
||||
tokenizer.dispose(); // Second call should not throw
|
||||
|
||||
expect(mockFree).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
});
|
||||
|
||||
describe('lazy initialization', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should not initialize tiktoken until first use', () => {
|
||||
expect(mockGetEncoding).not.toHaveBeenCalled();
|
||||
});
|
||||
|
||||
it('should initialize tiktoken on first calculateTokens call', async () => {
|
||||
await tokenizer.calculateTokens('test');
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
|
||||
it('should not reinitialize tiktoken on subsequent calls', async () => {
|
||||
await tokenizer.calculateTokens('test1');
|
||||
await tokenizer.calculateTokens('test2');
|
||||
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
});
|
||||
|
||||
it('should initialize tiktoken on first calculateTokensBatch call', async () => {
|
||||
await tokenizer.calculateTokensBatch(['test']);
|
||||
expect(mockGetEncoding).toHaveBeenCalledTimes(1);
|
||||
it('should maintain async interface for calculateTokensBatch', async () => {
|
||||
const result = tokenizer.calculateTokensBatch(['test']);
|
||||
expect(result).toBeInstanceOf(Promise);
|
||||
await expect(result).resolves.toEqual([1]);
|
||||
});
|
||||
});
|
||||
|
||||
describe('edge cases', () => {
|
||||
beforeEach(() => {
|
||||
tokenizer = new TextTokenizer();
|
||||
});
|
||||
|
||||
it('should handle very short text', async () => {
|
||||
const result = await tokenizer.calculateTokens('a');
|
||||
|
||||
if (mockGetEncoding.mock.calls.length > 0) {
|
||||
// If tiktoken was called, use its result
|
||||
expect(mockEncode).toHaveBeenCalledWith('a');
|
||||
} else {
|
||||
// If tiktoken failed, should use fallback: Math.ceil(1/4) = 1
|
||||
expect(result).toBe(1);
|
||||
}
|
||||
});
|
||||
|
||||
it('should handle text with only whitespace', async () => {
|
||||
const whitespaceText = ' \n\t ';
|
||||
const mockTokens = [1];
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
|
||||
const result = await tokenizer.calculateTokens(whitespaceText);
|
||||
|
||||
it('should handle text with only newlines', async () => {
|
||||
const text = '\n\n\n'; // 3 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// 3 / 4 = 0.75 -> ceil = 1
|
||||
expect(result).toBe(1);
|
||||
});
|
||||
|
||||
it('should handle special characters and symbols', async () => {
|
||||
const specialText = '!@#$%^&*()_+-=[]{}|;:,.<>?';
|
||||
const mockTokens = new Array(10);
|
||||
mockEncode.mockReturnValue(mockTokens);
|
||||
it('should handle text with tabs', async () => {
|
||||
const text = '\t\t\t\t'; // 4 ASCII chars
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// 4 / 4 = 1 -> ceil = 1
|
||||
expect(result).toBe(1);
|
||||
});
|
||||
|
||||
const result = await tokenizer.calculateTokens(specialText);
|
||||
it('should handle surrogate pairs correctly', async () => {
|
||||
// Character outside BMP (Basic Multilingual Plane)
|
||||
const text = '𝕳𝖊𝖑𝖑𝖔'; // Mathematical bold letters (2 UTF-16 units each)
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// Each character is 2 UTF-16 units, all non-ASCII
|
||||
// Total: 10 non-ASCII units
|
||||
// 10 * 1.1 = 11 -> ceil = 11
|
||||
expect(result).toBe(11);
|
||||
});
|
||||
|
||||
expect(result).toBe(10);
|
||||
it('should handle combining characters', async () => {
|
||||
// e + combining acute accent
|
||||
const text = 'e\u0301'; // 2 chars: 'e' (ASCII) + combining acute (non-ASCII)
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// ASCII: 1 / 4 = 0.25
|
||||
// Non-ASCII: 1 * 1.1 = 1.1
|
||||
// Total: 0.25 + 1.1 = 1.35 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
});
|
||||
|
||||
it('should handle accented characters', async () => {
|
||||
const text = 'café'; // 'caf' = 3 ASCII, 'é' = 1 non-ASCII
|
||||
const result = await tokenizer.calculateTokens(text);
|
||||
// ASCII: 3 / 4 = 0.75
|
||||
// Non-ASCII: 1 * 1.1 = 1.1
|
||||
// Total: 0.75 + 1.1 = 1.85 -> ceil = 2
|
||||
expect(result).toBe(2);
|
||||
});
|
||||
|
||||
it('should handle various unicode scripts', async () => {
|
||||
const cyrillic = 'Привет'; // 6 non-ASCII chars
|
||||
const arabic = 'مرحبا'; // 5 non-ASCII chars
|
||||
const japanese = 'こんにちは'; // 5 non-ASCII chars
|
||||
|
||||
const result1 = await tokenizer.calculateTokens(cyrillic);
|
||||
const result2 = await tokenizer.calculateTokens(arabic);
|
||||
const result3 = await tokenizer.calculateTokens(japanese);
|
||||
|
||||
// All should use 1.1 tokens per char
|
||||
expect(result1).toBe(7); // 6 * 1.1 = 6.6 -> ceil = 7
|
||||
expect(result2).toBe(6); // 5 * 1.1 = 5.5 -> ceil = 6
|
||||
expect(result3).toBe(6); // 5 * 1.1 = 5.5 -> ceil = 6
|
||||
});
|
||||
});
|
||||
|
||||
describe('large inputs', () => {
|
||||
it('should handle very long text', async () => {
|
||||
const longText = 'a'.repeat(200000); // 200k characters
|
||||
const result = await tokenizer.calculateTokens(longText);
|
||||
expect(result).toBe(50000); // 200000 / 4
|
||||
});
|
||||
|
||||
it('should handle large batches', async () => {
|
||||
const texts = Array.from({ length: 5000 }, () => 'Hello, world!');
|
||||
const result = await tokenizer.calculateTokensBatch(texts);
|
||||
expect(result).toHaveLength(5000);
|
||||
expect(result[0]).toBe(4);
|
||||
});
|
||||
});
|
||||
});
|
||||
|
||||
@@ -4,94 +4,55 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import type { TiktokenEncoding, Tiktoken } from 'tiktoken';
|
||||
import { get_encoding } from 'tiktoken';
|
||||
|
||||
/**
|
||||
* Text tokenizer for calculating text tokens using tiktoken
|
||||
* Text tokenizer for calculating text tokens using character-based estimation.
|
||||
*
|
||||
* Uses a lightweight character-based approach that is "good enough" for
|
||||
* guardrail features like sessionTokenLimit.
|
||||
*
|
||||
* Algorithm:
|
||||
* - ASCII characters: 0.25 tokens per char (4 chars = 1 token)
|
||||
* - Non-ASCII characters: 1.1 tokens per char (conservative for CJK, emoji, etc.)
|
||||
*/
|
||||
export class TextTokenizer {
|
||||
private encoding: Tiktoken | null = null;
|
||||
private encodingName: string;
|
||||
|
||||
constructor(encodingName: string = 'cl100k_base') {
|
||||
this.encodingName = encodingName;
|
||||
}
|
||||
|
||||
/**
|
||||
* Initialize the tokenizer (lazy loading)
|
||||
*/
|
||||
private async ensureEncoding(): Promise<void> {
|
||||
if (this.encoding) return;
|
||||
|
||||
try {
|
||||
// Use type assertion since we know the encoding name is valid
|
||||
this.encoding = get_encoding(this.encodingName as TiktokenEncoding);
|
||||
} catch (error) {
|
||||
console.warn(
|
||||
`Failed to load tiktoken with encoding ${this.encodingName}:`,
|
||||
error,
|
||||
);
|
||||
this.encoding = null;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Calculate tokens for text content
|
||||
*
|
||||
* @param text - The text to estimate tokens for
|
||||
* @returns The estimated token count
|
||||
*/
|
||||
async calculateTokens(text: string): Promise<number> {
|
||||
if (!text) return 0;
|
||||
|
||||
await this.ensureEncoding();
|
||||
|
||||
if (this.encoding) {
|
||||
try {
|
||||
return this.encoding.encode(text).length;
|
||||
} catch (error) {
|
||||
console.warn('Error encoding text with tiktoken:', error);
|
||||
}
|
||||
}
|
||||
|
||||
// Fallback: rough approximation using character count
|
||||
// This is a conservative estimate: 1 token ≈ 4 characters for most languages
|
||||
return Math.ceil(text.length / 4);
|
||||
return this.calculateTokensSync(text);
|
||||
}
|
||||
|
||||
/**
|
||||
* Calculate tokens for multiple text strings in parallel
|
||||
* Calculate tokens for multiple text strings
|
||||
*
|
||||
* @param texts - Array of text strings to estimate tokens for
|
||||
* @returns Array of token counts corresponding to each input text
|
||||
*/
|
||||
async calculateTokensBatch(texts: string[]): Promise<number[]> {
|
||||
await this.ensureEncoding();
|
||||
|
||||
if (this.encoding) {
|
||||
try {
|
||||
return texts.map((text) => {
|
||||
if (!text) return 0;
|
||||
// this.encoding may be null, add a null check to satisfy lint
|
||||
return this.encoding ? this.encoding.encode(text).length : 0;
|
||||
});
|
||||
} catch (error) {
|
||||
console.warn('Error encoding texts with tiktoken:', error);
|
||||
// In case of error, return fallback estimation for all texts
|
||||
return texts.map((text) => Math.ceil((text || '').length / 4));
|
||||
}
|
||||
}
|
||||
|
||||
// Fallback for batch processing
|
||||
return texts.map((text) => Math.ceil((text || '').length / 4));
|
||||
return texts.map((text) => this.calculateTokensSync(text));
|
||||
}
|
||||
|
||||
/**
|
||||
* Dispose of resources
|
||||
*/
|
||||
dispose(): void {
|
||||
if (this.encoding) {
|
||||
try {
|
||||
this.encoding.free();
|
||||
} catch (error) {
|
||||
console.warn('Error freeing tiktoken encoding:', error);
|
||||
}
|
||||
this.encoding = null;
|
||||
private calculateTokensSync(text: string): number {
|
||||
if (!text || text.length === 0) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
let asciiChars = 0;
|
||||
let nonAsciiChars = 0;
|
||||
|
||||
for (let i = 0; i < text.length; i++) {
|
||||
const charCode = text.charCodeAt(i);
|
||||
if (charCode < 128) {
|
||||
asciiChars++;
|
||||
} else {
|
||||
nonAsciiChars++;
|
||||
}
|
||||
}
|
||||
|
||||
const tokens = asciiChars / 4 + nonAsciiChars * 1.1;
|
||||
return Math.ceil(tokens);
|
||||
}
|
||||
}
|
||||
|
||||
@@ -4,8 +4,6 @@
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import type { CountTokensParameters } from '@google/genai';
|
||||
|
||||
/**
|
||||
* Token calculation result for different content types
|
||||
*/
|
||||
@@ -23,14 +21,6 @@ export interface TokenCalculationResult {
|
||||
processingTime: number;
|
||||
}
|
||||
|
||||
/**
|
||||
* Configuration for token calculation
|
||||
*/
|
||||
export interface TokenizerConfig {
|
||||
/** Custom text tokenizer encoding (defaults to cl100k_base) */
|
||||
textEncoding?: string;
|
||||
}
|
||||
|
||||
/**
|
||||
* Image metadata extracted from base64 data
|
||||
*/
|
||||
@@ -44,21 +34,3 @@ export interface ImageMetadata {
|
||||
/** Size of the base64 data in bytes */
|
||||
dataSize: number;
|
||||
}
|
||||
|
||||
/**
|
||||
* Request tokenizer interface
|
||||
*/
|
||||
export interface RequestTokenizer {
|
||||
/**
|
||||
* Calculate tokens for a request
|
||||
*/
|
||||
calculateTokens(
|
||||
request: CountTokensParameters,
|
||||
config?: TokenizerConfig,
|
||||
): Promise<TokenCalculationResult>;
|
||||
|
||||
/**
|
||||
* Dispose of resources (worker threads, etc.)
|
||||
*/
|
||||
dispose(): Promise<void>;
|
||||
}
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
{
|
||||
"name": "@qwen-code/sdk",
|
||||
"version": "0.1.2",
|
||||
"version": "0.1.3",
|
||||
"description": "TypeScript SDK for programmatic access to qwen-code CLI",
|
||||
"main": "./dist/index.cjs",
|
||||
"module": "./dist/index.mjs",
|
||||
@@ -46,8 +46,7 @@
|
||||
},
|
||||
"dependencies": {
|
||||
"@modelcontextprotocol/sdk": "^1.25.1",
|
||||
"zod": "^3.25.0",
|
||||
"tiktoken": "^1.0.21"
|
||||
"zod": "^3.25.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/node": "^20.14.0",
|
||||
|
||||
@@ -125,8 +125,9 @@ function normalizeForRegex(dirPath: string): string {
|
||||
function tryResolveCliFromImportMeta(): string | null {
|
||||
try {
|
||||
if (typeof import.meta !== 'undefined' && import.meta.url) {
|
||||
const cliUrl = new URL('./cli/cli.js', import.meta.url);
|
||||
const cliPath = fileURLToPath(cliUrl);
|
||||
const currentFilePath = fileURLToPath(import.meta.url);
|
||||
const currentDir = path.dirname(currentFilePath);
|
||||
const cliPath = path.join(currentDir, 'cli', 'cli.js');
|
||||
if (fs.existsSync(cliPath)) {
|
||||
return cliPath;
|
||||
}
|
||||
|
||||
@@ -98,17 +98,6 @@ console.log('Creating package.json for distribution...');
|
||||
const rootPackageJson = JSON.parse(
|
||||
fs.readFileSync(path.join(rootDir, 'package.json'), 'utf-8'),
|
||||
);
|
||||
const corePackageJson = JSON.parse(
|
||||
fs.readFileSync(
|
||||
path.join(rootDir, 'packages', 'core', 'package.json'),
|
||||
'utf-8',
|
||||
),
|
||||
);
|
||||
|
||||
const runtimeDependencies = {};
|
||||
if (corePackageJson.dependencies?.tiktoken) {
|
||||
runtimeDependencies.tiktoken = corePackageJson.dependencies.tiktoken;
|
||||
}
|
||||
|
||||
// Create a clean package.json for the published package
|
||||
const distPackageJson = {
|
||||
@@ -124,7 +113,7 @@ const distPackageJson = {
|
||||
},
|
||||
files: ['cli.js', 'vendor', '*.sb', 'README.md', 'LICENSE', 'locales'],
|
||||
config: rootPackageJson.config,
|
||||
dependencies: runtimeDependencies,
|
||||
dependencies: {},
|
||||
optionalDependencies: {
|
||||
'@lydell/node-pty': '1.1.0',
|
||||
'@lydell/node-pty-darwin-arm64': '1.1.0',
|
||||
|
||||
Reference in New Issue
Block a user