mirror of
https://github.com/QwenLM/qwen-code.git
synced 2026-01-17 06:19:13 +00:00
Compare commits
1 Commits
mingholy/f
...
docs/code-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
2852f48a4a |
@@ -5,11 +5,13 @@ Qwen Code supports two authentication methods. Pick the one that matches how you
|
||||
- **Qwen OAuth (recommended)**: sign in with your `qwen.ai` account in a browser.
|
||||
- **OpenAI-compatible API**: use an API key (OpenAI or any OpenAI-compatible provider / endpoint).
|
||||
|
||||
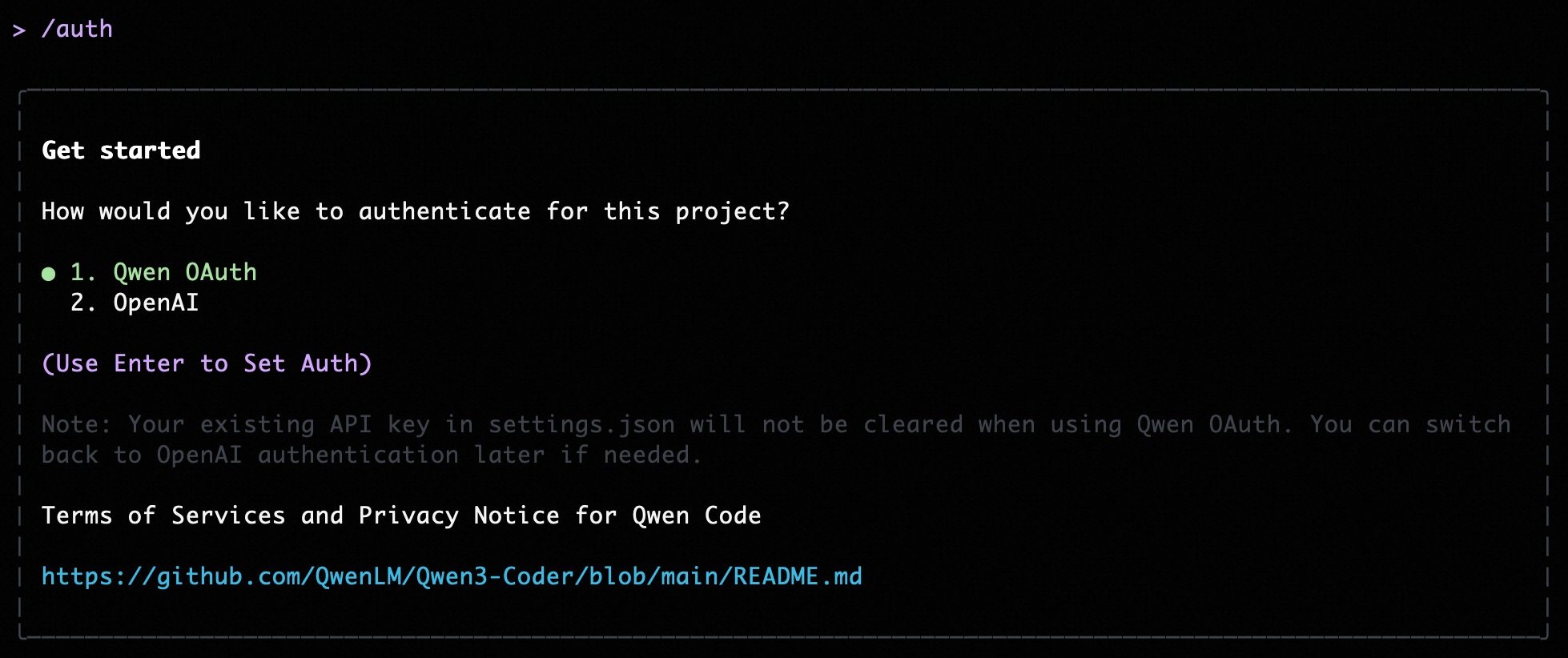
|
||||
|
||||
## Option 1: Qwen OAuth (recommended & free) 👍
|
||||
|
||||
Use this if you want the simplest setup and you’re using Qwen models.
|
||||
Use this if you want the simplest setup and you're using Qwen models.
|
||||
|
||||
- **How it works**: on first start, Qwen Code opens a browser login page. After you finish, credentials are cached locally so you usually won’t need to log in again.
|
||||
- **How it works**: on first start, Qwen Code opens a browser login page. After you finish, credentials are cached locally so you usually won't need to log in again.
|
||||
- **Requirements**: a `qwen.ai` account + internet access (at least for the first login).
|
||||
- **Benefits**: no API key management, automatic credential refresh.
|
||||
- **Cost & quota**: free, with a quota of **60 requests/minute** and **2,000 requests/day**.
|
||||
@@ -24,15 +26,54 @@ qwen
|
||||
|
||||
Use this if you want to use OpenAI models or any provider that exposes an OpenAI-compatible API (e.g. OpenAI, Azure OpenAI, OpenRouter, ModelScope, Alibaba Cloud Bailian, or a self-hosted compatible endpoint).
|
||||
|
||||
### Quick start (interactive, recommended for local use)
|
||||
### Recommended: Coding Plan (subscription-based) 🚀
|
||||
|
||||
When you choose the OpenAI-compatible option in the CLI, it will prompt you for:
|
||||
Use this if you want predictable costs with higher usage quotas for the qwen3-coder-plus model.
|
||||
|
||||
- **API key**
|
||||
- **Base URL** (default: `https://api.openai.com/v1`)
|
||||
- **Model** (default: `gpt-4o`)
|
||||
> [!IMPORTANT]
|
||||
>
|
||||
> Coding Plan is only available for users in China mainland (Beijing region).
|
||||
|
||||
> **Note:** the CLI may display the key in plain text for verification. Make sure your terminal is not being recorded or shared.
|
||||
- **How it works**: subscribe to the Coding Plan with a fixed monthly fee, then configure Qwen Code to use the dedicated endpoint and your subscription API key.
|
||||
- **Requirements**: an active Coding Plan subscription from [Alibaba Cloud Bailian](https://bailian.console.aliyun.com/cn-beijing/?tab=globalset#/efm/coding_plan).
|
||||
- **Benefits**: higher usage quotas, predictable monthly costs, access to latest qwen3-coder-plus model.
|
||||
- **Cost & quota**: varies by plan (see table below).
|
||||
|
||||
#### Coding Plan Pricing & Quotas
|
||||
|
||||
| Feature | Lite Basic Plan | Pro Advanced Plan |
|
||||
| :------------------ | :-------------------- | :-------------------- |
|
||||
| **Price** | ¥40/month | ¥200/month |
|
||||
| **5-Hour Limit** | Up to 1,200 requests | Up to 6,000 requests |
|
||||
| **Weekly Limit** | Up to 9,000 requests | Up to 45,000 requests |
|
||||
| **Monthly Limit** | Up to 18,000 requests | Up to 90,000 requests |
|
||||
| **Supported Model** | qwen3-coder-plus | qwen3-coder-plus |
|
||||
|
||||
#### Quick Setup for Coding Plan
|
||||
|
||||
When you select the OpenAI-compatible option in the CLI, enter these values:
|
||||
|
||||
- **API key**: `sk-sp-xxxxx`
|
||||
- **Base URL**: `https://coding.dashscope.aliyuncs.com/v1`
|
||||
- **Model**: `qwen3-coder-plus`
|
||||
|
||||
> **Note**: Coding Plan API keys have the format `sk-sp-xxxxx`, which is different from standard Alibaba Cloud API keys.
|
||||
|
||||
#### Configure via Environment Variables
|
||||
|
||||
Set these environment variables to use Coding Plan:
|
||||
|
||||
```bash
|
||||
export OPENAI_API_KEY="your-coding-plan-api-key" # Format: sk-sp-xxxxx
|
||||
export OPENAI_BASE_URL="https://coding.dashscope.aliyuncs.com/v1"
|
||||
export OPENAI_MODEL="qwen3-coder-plus"
|
||||
```
|
||||
|
||||
For more details about Coding Plan, including subscription options and troubleshooting, see the [full Coding Plan documentation](https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc/?type=model&url=3005961).
|
||||
|
||||
### Other OpenAI-compatible Providers
|
||||
|
||||
If you are using other providers (OpenAI, Azure, local LLMs, etc.), use the following configuration methods.
|
||||
|
||||
### Configure via command-line arguments
|
||||
|
||||
|
||||
@@ -28,7 +28,6 @@ type RawMessageStreamEvent = Anthropic.RawMessageStreamEvent;
|
||||
import { getDefaultTokenizer } from '../../utils/request-tokenizer/index.js';
|
||||
import { safeJsonParse } from '../../utils/safeJsonParse.js';
|
||||
import { AnthropicContentConverter } from './converter.js';
|
||||
import { buildRuntimeFetchOptions } from '../../utils/runtimeFetchOptions.js';
|
||||
|
||||
type StreamingBlockState = {
|
||||
type: string;
|
||||
@@ -55,9 +54,6 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
) {
|
||||
const defaultHeaders = this.buildHeaders();
|
||||
const baseURL = contentGeneratorConfig.baseUrl;
|
||||
// Configure runtime options to ensure user-configured timeout works as expected
|
||||
// bodyTimeout is always disabled (0) to let Anthropic SDK timeout control the request
|
||||
const runtimeOptions = buildRuntimeFetchOptions('anthropic');
|
||||
|
||||
this.client = new Anthropic({
|
||||
apiKey: contentGeneratorConfig.apiKey,
|
||||
@@ -65,7 +61,6 @@ export class AnthropicContentGenerator implements ContentGenerator {
|
||||
timeout: contentGeneratorConfig.timeout,
|
||||
maxRetries: contentGeneratorConfig.maxRetries,
|
||||
defaultHeaders,
|
||||
...runtimeOptions,
|
||||
});
|
||||
|
||||
this.converter = new AnthropicContentConverter(
|
||||
|
||||
@@ -16,7 +16,6 @@ import type {
|
||||
ChatCompletionContentPartWithCache,
|
||||
ChatCompletionToolWithCache,
|
||||
} from './types.js';
|
||||
import { buildRuntimeFetchOptions } from '../../../utils/runtimeFetchOptions.js';
|
||||
|
||||
export class DashScopeOpenAICompatibleProvider
|
||||
implements OpenAICompatibleProvider
|
||||
@@ -69,16 +68,12 @@ export class DashScopeOpenAICompatibleProvider
|
||||
maxRetries = DEFAULT_MAX_RETRIES,
|
||||
} = this.contentGeneratorConfig;
|
||||
const defaultHeaders = this.buildHeaders();
|
||||
// Configure fetch options to ensure user-configured timeout works as expected
|
||||
// bodyTimeout is always disabled (0) to let OpenAI SDK timeout control the request
|
||||
const fetchOptions = buildRuntimeFetchOptions('openai');
|
||||
return new OpenAI({
|
||||
apiKey,
|
||||
baseURL: baseUrl,
|
||||
timeout,
|
||||
maxRetries,
|
||||
defaultHeaders,
|
||||
...(fetchOptions ? { fetchOptions } : {}),
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
@@ -4,7 +4,6 @@ import type { Config } from '../../../config/config.js';
|
||||
import type { ContentGeneratorConfig } from '../../contentGenerator.js';
|
||||
import { DEFAULT_TIMEOUT, DEFAULT_MAX_RETRIES } from '../constants.js';
|
||||
import type { OpenAICompatibleProvider } from './types.js';
|
||||
import { buildRuntimeFetchOptions } from '../../../utils/runtimeFetchOptions.js';
|
||||
|
||||
/**
|
||||
* Default provider for standard OpenAI-compatible APIs
|
||||
@@ -44,16 +43,12 @@ export class DefaultOpenAICompatibleProvider
|
||||
maxRetries = DEFAULT_MAX_RETRIES,
|
||||
} = this.contentGeneratorConfig;
|
||||
const defaultHeaders = this.buildHeaders();
|
||||
// Configure fetch options to ensure user-configured timeout works as expected
|
||||
// bodyTimeout is always disabled (0) to let OpenAI SDK timeout control the request
|
||||
const fetchOptions = buildRuntimeFetchOptions('openai');
|
||||
return new OpenAI({
|
||||
apiKey,
|
||||
baseURL: baseUrl,
|
||||
timeout,
|
||||
maxRetries,
|
||||
defaultHeaders,
|
||||
...(fetchOptions ? { fetchOptions } : {}),
|
||||
});
|
||||
}
|
||||
|
||||
|
||||
@@ -1,167 +0,0 @@
|
||||
/**
|
||||
* @license
|
||||
* Copyright 2025 Qwen Team
|
||||
* SPDX-License-Identifier: Apache-2.0
|
||||
*/
|
||||
|
||||
import { EnvHttpProxyAgent } from 'undici';
|
||||
|
||||
/**
|
||||
* JavaScript runtime type
|
||||
*/
|
||||
export type Runtime = 'node' | 'bun' | 'unknown';
|
||||
|
||||
/**
|
||||
* Detect the current JavaScript runtime
|
||||
*/
|
||||
export function detectRuntime(): Runtime {
|
||||
if (typeof process !== 'undefined' && process.versions?.['bun']) {
|
||||
return 'bun';
|
||||
}
|
||||
if (typeof process !== 'undefined' && process.versions?.node) {
|
||||
return 'node';
|
||||
}
|
||||
return 'unknown';
|
||||
}
|
||||
|
||||
/**
|
||||
* Runtime fetch options for OpenAI SDK
|
||||
*/
|
||||
export type OpenAIRuntimeFetchOptions =
|
||||
| {
|
||||
dispatcher?: EnvHttpProxyAgent;
|
||||
timeout?: false;
|
||||
}
|
||||
| undefined;
|
||||
|
||||
/**
|
||||
* Runtime fetch options for Anthropic SDK
|
||||
*/
|
||||
export type AnthropicRuntimeFetchOptions = {
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
httpAgent?: any;
|
||||
// eslint-disable-next-line @typescript-eslint/no-explicit-any
|
||||
fetch?: any;
|
||||
};
|
||||
|
||||
/**
|
||||
* SDK type identifier
|
||||
*/
|
||||
export type SDKType = 'openai' | 'anthropic';
|
||||
|
||||
/**
|
||||
* Build runtime-specific fetch options for OpenAI SDK
|
||||
*/
|
||||
export function buildRuntimeFetchOptions(
|
||||
sdkType: 'openai',
|
||||
): OpenAIRuntimeFetchOptions;
|
||||
/**
|
||||
* Build runtime-specific fetch options for Anthropic SDK
|
||||
*/
|
||||
export function buildRuntimeFetchOptions(
|
||||
sdkType: 'anthropic',
|
||||
): AnthropicRuntimeFetchOptions;
|
||||
/**
|
||||
* Build runtime-specific fetch options based on the detected runtime and SDK type
|
||||
* This function applies runtime-specific configurations to handle timeout differences
|
||||
* across Node.js and Bun, ensuring user-configured timeout works as expected.
|
||||
*
|
||||
* @param sdkType - The SDK type ('openai' or 'anthropic') to determine return type
|
||||
* @returns Runtime-specific options compatible with the specified SDK
|
||||
*/
|
||||
export function buildRuntimeFetchOptions(
|
||||
sdkType: SDKType,
|
||||
): OpenAIRuntimeFetchOptions | AnthropicRuntimeFetchOptions {
|
||||
const runtime = detectRuntime();
|
||||
|
||||
// Always disable bodyTimeout (set to 0) to let SDK's timeout parameter
|
||||
// control the total request time. bodyTimeout only monitors intervals between
|
||||
// data chunks, not the total request time, so we disable it to ensure user-configured
|
||||
// timeout works as expected for both streaming and non-streaming requests.
|
||||
|
||||
switch (runtime) {
|
||||
case 'bun': {
|
||||
if (sdkType === 'openai') {
|
||||
// Bun: Disable built-in 300s timeout to let OpenAI SDK timeout control
|
||||
// This ensures user-configured timeout works as expected without interference
|
||||
return {
|
||||
timeout: false,
|
||||
};
|
||||
} else {
|
||||
// Bun: Use custom fetch to disable built-in 300s timeout
|
||||
// This allows Anthropic SDK timeout to control the request
|
||||
// Note: Bun's fetch automatically uses proxy settings from environment variables
|
||||
// (HTTP_PROXY, HTTPS_PROXY, NO_PROXY), so proxy behavior is preserved
|
||||
const bunFetch: typeof fetch = async (
|
||||
input: RequestInfo | URL,
|
||||
init?: RequestInit,
|
||||
) => {
|
||||
const bunFetchOptions: RequestInit = {
|
||||
...init,
|
||||
// @ts-expect-error - Bun-specific timeout option
|
||||
timeout: false,
|
||||
};
|
||||
return fetch(input, bunFetchOptions);
|
||||
};
|
||||
return {
|
||||
fetch: bunFetch,
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
case 'node': {
|
||||
// Node.js: Use EnvHttpProxyAgent to configure proxy and disable bodyTimeout
|
||||
// EnvHttpProxyAgent automatically reads proxy settings from environment variables
|
||||
// (HTTP_PROXY, HTTPS_PROXY, NO_PROXY, etc.) to preserve proxy functionality
|
||||
// bodyTimeout is always 0 (disabled) to let SDK timeout control the request
|
||||
try {
|
||||
const agent = new EnvHttpProxyAgent({
|
||||
bodyTimeout: 0, // Disable to let SDK timeout control total request time
|
||||
});
|
||||
|
||||
if (sdkType === 'openai') {
|
||||
return {
|
||||
dispatcher: agent,
|
||||
};
|
||||
} else {
|
||||
return {
|
||||
httpAgent: agent,
|
||||
};
|
||||
}
|
||||
} catch {
|
||||
// If undici is not available, return appropriate default
|
||||
if (sdkType === 'openai') {
|
||||
return undefined;
|
||||
} else {
|
||||
return {};
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
default: {
|
||||
// Unknown runtime: Try to use EnvHttpProxyAgent if available
|
||||
// EnvHttpProxyAgent automatically reads proxy settings from environment variables
|
||||
try {
|
||||
const agent = new EnvHttpProxyAgent({
|
||||
bodyTimeout: 0, // Disable to let SDK timeout control total request time
|
||||
});
|
||||
|
||||
if (sdkType === 'openai') {
|
||||
return {
|
||||
dispatcher: agent,
|
||||
};
|
||||
} else {
|
||||
return {
|
||||
httpAgent: agent,
|
||||
};
|
||||
}
|
||||
} catch {
|
||||
if (sdkType === 'openai') {
|
||||
return undefined;
|
||||
} else {
|
||||
return {};
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
Reference in New Issue
Block a user